Explore large language models on Apple silicon with MLX
2025年6月9日
一句话判断
如果你需要在 Mac 上跑比 Foundation Models 更大的 LLM(比如 70B+),或者要做 fine-tuning,MLX 是 Apple 官方给的答案。一行命令跑推理,一行命令做 LoRA 微调,一行命令量化到 4-bit。Python 和 Swift 双栈支持,全部开源。
这场 Session 讲了什么
Angelos 展示了 MLX 在 Apple Silicon 上运行大语言模型的完整工作流。
MLX LM 是核心工具包。 pip install mlx-lm 就能用。CLI 工具让你不用写代码就能生成文本、量化模型、微调模型。Python API 给你细粒度控制。
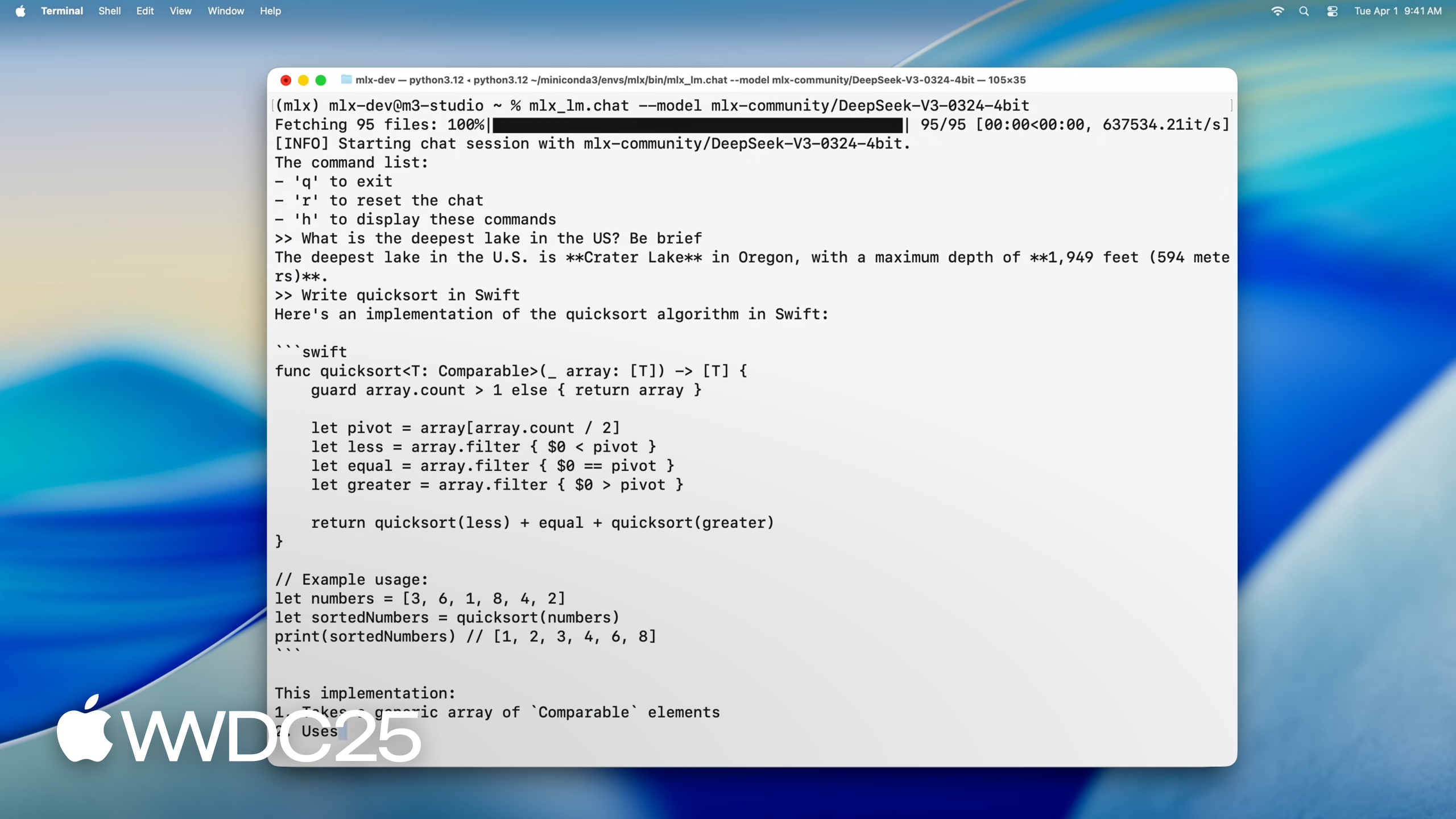
文本生成: CLI 用 mlx_lm.generate --model <model> --prompt <text>,支持 temperature、top-p、max tokens 等参数。Python API 用 load + generate 两个函数。模型从 Hugging Face 自动下载。
KV Cache 管理多轮对话。 make_prompt_cache() 创建缓存对象,跨多次 generate 调用复用,避免重复计算 attention。可以在运行中编辑历史、保存/恢复对话状态。
模型量化: mlx_lm.convert --model <model> --quantize --mlx-path <output> 一步完成下载 + 量化 + 保存。Python API 支持按层设置不同量化精度——embedding 和 projection 层用 6-bit,其他层用 4-bit,平衡质量和效率。
微调: 支持 full fine-tuning 和 LoRA adapter training。mlx_lm.lora --model <model> --train --data <dataset> 启动 LoRA 微调。可以在 4-bit 量化模型上训练 adapter,内存占用降 3.5 倍。训练完成后 mlx_lm.fuse 把 adapter 合并回基座模型,保持量化精度不变。
Swift 集成: 完整示例 28 行代码。创建 ModelContainer actor 管理并发访问,tokenize prompt,运行生成循环。多轮对话只需额外加一行 KV Cache 代码。
大模型演示: 在 M3 Ultra(512GB 统一内存)上跑了 DeepSeek 670B 参数模型(4.5-bit 量化,权重约 380GB),实时交互速度超过阅读速度。
值得深挖的点
MLX 利用统一内存是关键差异。 传统 GPU 方案需要 CPU->GPU 数据拷贝,MLX 的 CPU 和 GPU 直接操作同一块内存,零拷贝。这让大模型在 Apple Silicon 上的效率远超同价位的 NVIDIA 方案(在统一内存容量范围内)。
量化时按层区分精度是最佳实践。 Embedding 和 projection 层对量化更敏感,用更高精度(6-bit)。中间的 transformer layers 用 4-bit 几乎没有质量损失。
LoRA + 量化模型的组合是消费级硬件微调的关键。 传统上微调需要大量显存,但在 4-bit 量化模型上训练 LoRA adapter,M3 Ultra 上甚至可以微调 70B+ 的模型。
Token iterator 在 Swift 中给你逐 token 的控制权。 不像 Python 的 generate 一步返回完整文本,Swift 的 iterator 可以在每个 token 生成后做处理——适合实现打字机效果或实时流式 UI。
代码片段
CLI 一行命令做 LoRA 微调(在量化模型上):
# 量化模型
mlx_lm.convert --model mistralai/Mistral-7B-v0.3 \
--quantize --mlx-path ./mistral-4bit
# LoRA 微调(在 4-bit 模型上)
mlx_lm.lora --model ./mistral-4bit \
--train --data ./my_dataset \
--iters 1000 --learning-rate 1e-5
# 合并 adapter
mlx_lm.fuse --model ./mistral-4bit \
--adapter-path ./adapters \
--mlx-path ./mistral-fused
# 上传到 Hugging Face
mlx_lm.fuse --model ./mistral-4bit \
--upload-repo my-org/mistral-finetunedPython API 按层差异化量化:
from mlx_lm import load, convert
def quantization_predicate(layer_path, layer):
# Embedding 和 projection 用 6-bit,其余用 4-bit
if "embed" in layer_path or "proj" in layer_path:
return {"bits": 6}
return {"bits": 4}
convert(
hf_path="mistralai/Mistral-7B-v0.3",
mlx_path="./mistral-mixed-q",
quant_predicate=quantization_predicate,
)Swift 中 28 行跑推理:
import MLX
import MLXLLM
import MLXLMCommon
let modelContainer = try await loadModelContainer(
id: "mlx-community/Mistral-7B-v0.3-4bit"
)
try await modelContainer.perform { context in
let input = try await context.processor.prepare(
input: UserInput(prompt: "What is the deepest lake in the US?")
)
let tokens = try generate(
input: input, parameters: GenerateParameters(), context: context
) { tokens in
if let last = tokens.last {
let text = context.tokenizer.decode(tokens: [last])
print(text, terminator: "")
}
return tokens.count < 512 ? .more : .stop
}
}最佳实践
选择模型大小要匹配硬件。 模型权重(GB)≈ 参数量 × 量化位数 / 8。70B 4-bit 模型约需 35GB,128GB 的 M4 Max 跑得动。670B 需要 380GB+,得上 M3 Ultra 512GB。
生成时用 KV Cache 避免重复计算。 第一次 prompt 处理是 compute-bound(预填充 KV),后续 token 生成是 memory-bound(逐 token 读取 KV cache)。多轮对话必须用 cache 否则每次都要重新处理全部历史。
微调数据集格式用 Hugging Face 标准格式。 MLX LM 直接兼容,不需要特殊转换。数据集放在本地目录,通过 --data 参数指定路径。
Profiling 用 mlx_lm.generate --time。 CLI 内置了 token 生成速度和首次 token 延迟的计时,快速判断你的模型+硬件组合是否达到预期性能。
还有什么值得关注
- MLX 全栈开源:C, C++, Python, Swift 四种语言的 API。Metal kernel 到高层 API 完全透明。
- MLX Swift 有独立的 example repository,包含图像生成(diffusion model)、语音识别等完整项目。
- 支持分布式推理和训练——多 GPU Mac Pro 可以并行跑更大模型。
- 支持 learned quantization——用小数据集微调量化参数,比静态量化效果更好。
- 配套视频:“Get Started with MLX for Apple Silicon” 适合 MLX 新手入门。
- 与 Session 286(Foundation Models framework)的关系:Foundation Models 是 3B 参数的端侧模型,面向 app 内嵌智能功能;MLX 是通用 ML 框架,面向需要更大模型或自定义训练的场景。