用 Metal 加速机器学习模型
Accelerate machine learning with Metal
2024年6月10日
一句话判断
MPS 和 MPSGraph 今年在 Transformer 模型优化上集中发力:融合 SDPA 算子、KV Cache 原地更新、4-bit 量化,再加上 FFT 加速和新的 MPSGraph Viewer,覆盖了从推理性能到可视化调试的完整链条。
这场 Session 讲了什么
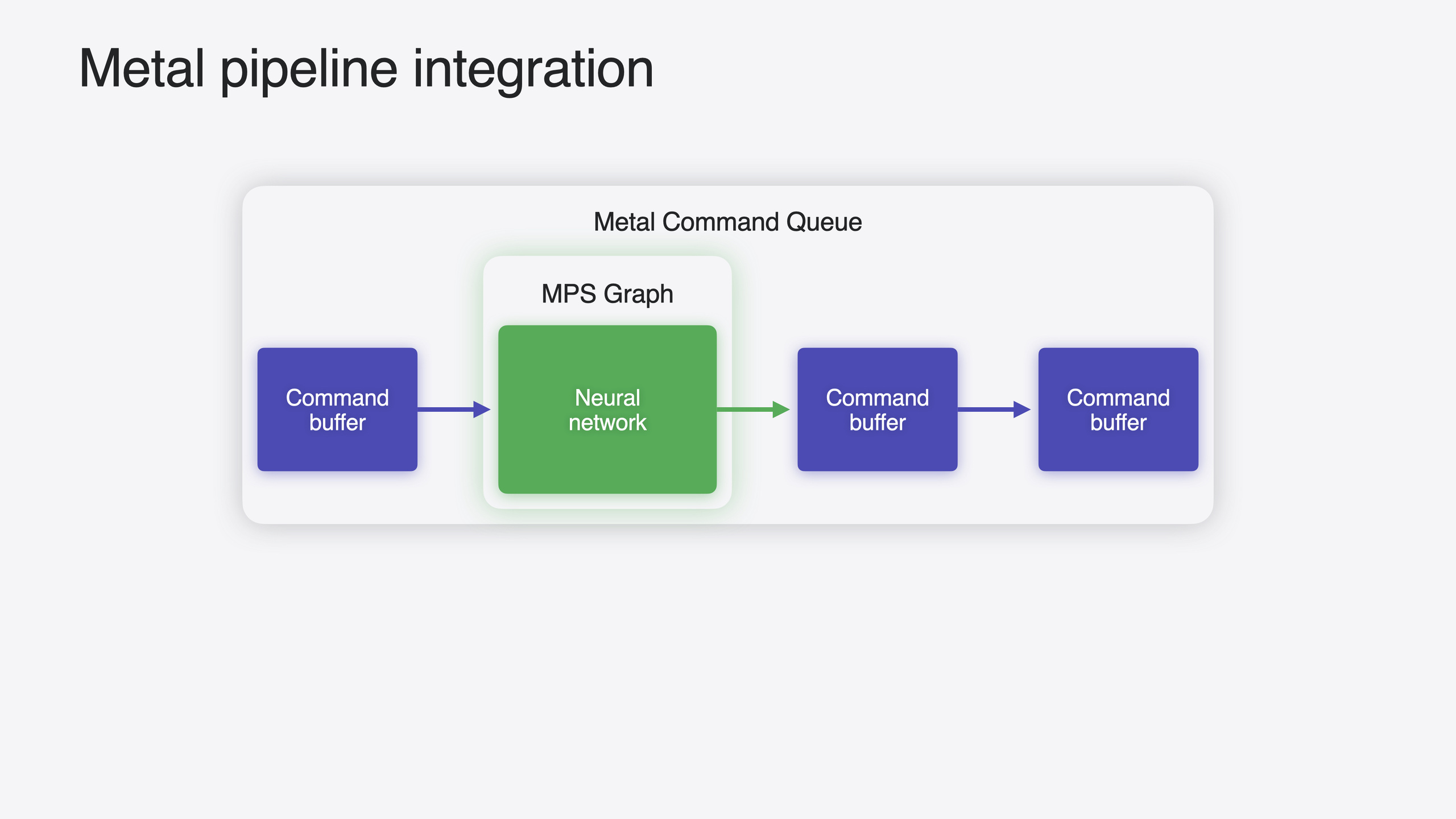
在 Apple 平台上部署机器学习模型有三个阶段:训练、部署准备、应用集成。这场 Session 聚焦在推理性能优化环节。
如果你的应用使用 Core ML 部署模型,MPSGraph 已经在底层提供 GPU 加速。你也可以用 PyTorch、TensorFlow、JAX 等框架训练模型,它们都构建在 Metal Performance Shaders Graph(MPSGraph)之上。在某些场景下你可能需要直接使用 MPSGraph:当你的应用本身就用 Metal,需要将 ML 任务与其他 GPU 工作排在一起;或者你需要共享底层 Metal 资源如 Buffer。
今年的更新分三个方向。针对 Transformer 模型的计算性能优化,包括融合 Scaled Dot-Product Attention(SDPA)算子和 KV Cache 原地更新。内存带宽优化,新增 4-bit 整数量化支持。质量改进,包括新的量化技术。此外还有 FFT 加速和 MPSGraph Viewer 可视化工具。
值得深挖的点
融合 SDPA 和 KV Cache 的组合拳
Transformer 模型的核心是 Multi-Head Attention 块中的 Scaled Dot-Product Attention。这个块内部包含多个连续运算:矩阵乘法、缩放、Softmax、再矩阵乘法。MPSGraph 现在提供了一个融合算子,将整个序列合并为单个 kernel 执行,减少了中间结果的读写开销。
但更大的性能提升来自 KV Cache 的正确使用。在自回归生成中,每次生成新 token 都需要把所有已生成 token 重新送入模型计算 Q、K、V 投影。K 和 V 的投影其实之前已经算过了,重复计算浪费算力。
解决方案是维护一个 KV Cache 张量来缓存已计算的 K 和 V 投影。关键是用 slice update 原地更新这个缓存,而不是每次迭代创建新张量。通过 MPSGraph 的 Variable 机制,你可以让图优化器理解这个更新是原地操作,避免额外的内存分配。生成新 token 时只需计算当前 token 的 K/V 投影,用 slice 提取缓存中的有效部分,然后传给 SDPA 算子。
4-bit 量化的工程实践
大型语言模型的权重通常用 16-bit 浮点表示,动辄几十 GB。MPS 之前支持 8-bit 整数量化(减半),今年新增 4-bit 整数格式(再减半)。
量化有两种主要技术。线性量化将 256 个(8-bit)或 16 个(4-bit)量化点均匀分布在数值范围上,简单但有精度损失。查找表(LUT)量化更适合权重分布不均匀的情况——当值集中在数轴的几个区域时,线性量化会浪费大量量化位。
MPSGraph 提供了 dequantize 方法来将量化值恢复为计算精度。关键决策是根据你的模型特点选择量化方案:如果权重分布相对均匀,4-bit 线性量化是最激进的压缩;如果分布不均匀,LUT 量化能以相同的位数保持更好的精度。
代码片段
融合 SDPA 算子
// 使用融合的 Scaled Dot-Product Attention 算子
// 将多个连续运算合并为单个高效 kernel
func buildSDPA(graph: MPSGraph,
query: MPSGraphTensor,
key: MPSGraphTensor,
value: MPSGraphTensor) -> MPSGraphTensor {
// 单个方法调用替代手动拼接多个运算
let attention = graph.scaledDotProductAttention(
withQuery: query,
key: key,
value: value
)
return attention
}KV Cache 原地更新
// 创建 KV Cache 占位符
let cachePlaceholder = MPSGraphTensor(
shape: [batchSize, numHeads, maxSeqLen, headDim]
)
// 用 Variable 包装,支持原地更新
let cacheVariable = graph.variable(with: cachePlaceholder)
// 每个新 token 的 K 投影插入缓存
let newKeyProjection: MPSGraphTensor = /* 当前 token 的 K 投影 */
// 使用 sliceUpdate 原地更新
let updatedCache = graph.sliceUpdateData(
newKeyProjection,
withUpdateTo: cacheVariable,
start: [0, 0, currentTokenIndex, 0], // 从当前位置插入
end: [batchSize, numHeads, currentTokenIndex + 1, headDim],
stride: [1, 1, 1, 1]
)
// 赋值回 Variable,MPSGraph 会优化为原地操作
cacheVariable.assign(updatedCache)
// 提取有效部分的缓存
let validCache = graph.slice(
cacheVariable,
start: [0, 0, 0, 0],
end: [batchSize, numHeads, currentTokenIndex + 1, headDim],
stride: [1, 1, 1, 1]
)
// 传给 SDPA 算子
let attention = graph.scaledDotProductAttention(
withQuery: currentQuery,
key: validCache,
value: validValueCache
)坑点:KV Cache 的 maxSeqLen 需要预先分配足够空间,如果序列长度超出预分配大小会导致越界。建议根据模型的最大上下文长度来设置 maxSeqLen。
4-bit 权重量化
// 线性量化:将 16-bit 权重压缩为 4-bit 整数
// 量化比例因子 = 最大绝对值 / 量化范围
let scale = maxAbsValue / 7.0 // 4-bit 范围: -8 到 7
// 反量化:将 4-bit 值恢复为计算精度
let dequantizedWeights = graph.dequantize(
quantizedWeights,
withScale: scaleTensor,
zeroPoint: zeroPointTensor,
dataType: .float16
)
// 查找表量化:适合权重分布不均匀的情况
// 权重集中在数轴某些区域时效果更好最佳实践
如果你的应用涉及 Transformer 模型推理,优先做三件事。第一,把手动实现的 SDPA 替换为融合算子,这是改动最小收益最大的优化。第二,为自回归场景实现 KV Cache,用 Variable + sliceUpdate 确保原地更新。第三,评估 4-bit 量化对你模型精度的影响——从 8-bit 降到 4-bit 内存带宽再减半,但需要验证输出质量是否可接受。量化方案的选择取决于权重分布:均匀分布用线性量化,集中分布用 LUT 量化。用 MPSGraph Viewer 在量化前后对比计算图,确认精度损失在可接受范围内。
还有什么值得关注
- MPSGraph Viewer 是新推出的可视化工具,可以查看 ML 模型的完整计算图
- FFT 加速支持基于频域的 ML 模型,覆盖了 Transformer 之外的另一类模型架构
- Core ML 底层自动使用这些 MPS/MPSGraph 优化,不需要手动调用