探索 Swift 性能
Explore Swift performance
2024年6月10日
一句话判断
John McCall 主讲的这场 Session 是近年来对 Swift 底层性能机制最清晰的解读——函数调度、内存分配、拷贝销毁、优化器行为,每个概念都配以编译器视角的解释,如果你需要做性能优化,这是必看的基础课。
这场 Session 讲了什么
Swift 的性能直觉不如 C 那么直接。C 到机器码的翻译几乎是字面的——局部变量在栈上,堆分配只有你显式调用 malloc 才会发生。Swift 引入了安全性和大量抽象工具(闭包、泛型等),这些抽象的实现成本不像 malloc 那样一目了然。
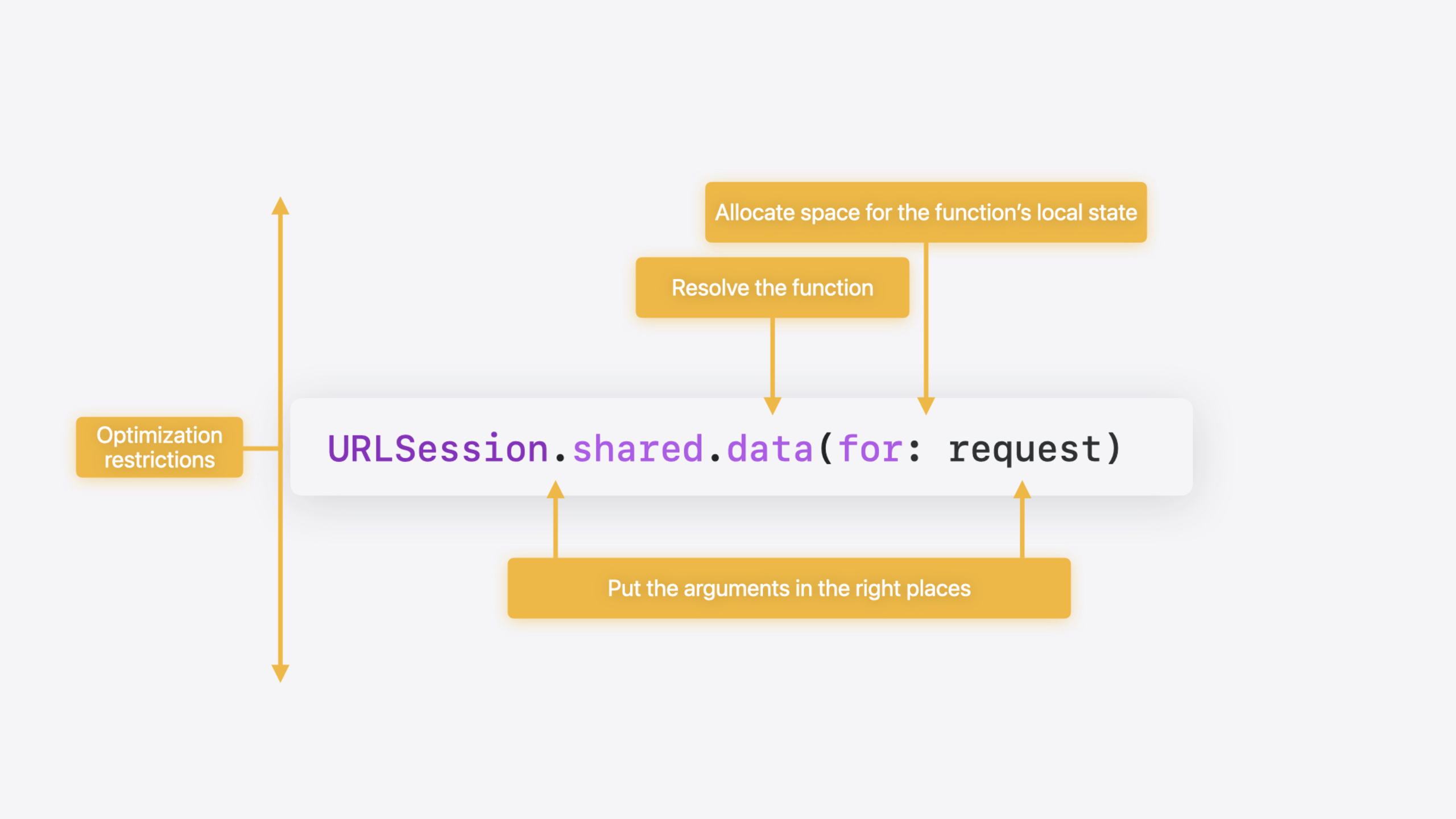
Session 把低层性能归纳为四个核心维度:函数调用开销(参数传递、地址解析、局部状态分配、以及对优化的阻碍)、数据表示的效率(内存布局是否浪费)、内存分配的时间消耗、以及值的拷贝和销毁成本。
Swift 有一个强大的优化器,能消除很多你看不到的性能问题。但优化器有极限——你写代码的方式会显著影响它能做多少优化。John McCall 给出了一个务实的建议:当性能很重要时,你需要定期监控它。在自顶向下的性能调查中找到热点后,想办法测量它们,然后把测量自动化到开发流程中。这样无论你是搞坏了优化器还是不小心引入了二次方算法,都能及时捕获。
值得深挖的点
静态调度 vs 动态调度的选择比你想象的影响更大
函数调度方式决定了两个关键问题:运行时调用有多快,以及编译器能做多少优化。静态调度(编译时知道调用哪个函数)允许内联和泛型特化等优化。动态调度(运行时才确定)则阻止了这些优化。
在 Swift 中,调度方式由方法的声明位置决定。一个方法如果声明在 protocol 的主体中(protocol requirement),调用它使用动态调度。如果声明在 protocol extension 中,调用使用静态调度。这不仅是性能差异——语义上也不同。protocol requirement 的方法会被类型覆盖,extension 中的方法不会。
这个区别在实践中意味着:如果性能关键路径上有一个协议方法被频繁调用,考虑它是否真的需要是 protocol requirement。如果类型的静态信息在调用点可用,把它移到 extension 中可以获得静态调度的性能优势。但要注意,这同时改变了多态行为的语义。
CallFrame 的布局决定了局部变量的成本
函数执行需要内存来存储局部状态。同步函数在 C 栈上分配 CallFrame——只需要减去栈指针就能分配,函数结束时加回来就释放。理想情况下,所有局部状态都成为 CallFrame 的”字段”。
这个机制在编译后的汇编中清晰可见:函数开头有一条 sub 指令从栈指针减去固定大小(比如 208 字节),函数结尾有一条 add 指令加回来。这个减法指令是函数必须执行的(至少要保存返回地址),所以减去更大的常量不花额外时间——局部变量的栈分配实际上是免费的。
问题在于,不是所有值都能放在 CallFrame 里。如果一个值的生命周期可能超过函数返回(比如被闭包捕获),或者大小在编译时不确定(比如 existential container),它就需要在堆上分配。堆分配涉及锁、搜索空闲列表、可能的系统调用,成本远高于栈分配。理解你的值是否逃逸出函数,是控制内存分配成本的关键。
代码片段
Protocol Requirement vs Extension 的调度差异
protocol Drawable {
// protocol requirement:动态调度
func draw()
}
extension Drawable {
// protocol extension:静态调度
// 但如果类型通过 existential 调用,仍可能走动态路径
func drawWithAnimation() {
// 这个方法在编译时就能确定具体实现
print("准备动画")
draw() // 这个调用是动态调度
print("完成动画")
}
}
struct Circle: Drawable {
func draw() {
print("绘制圆形")
}
}
// 性能差异的体现
func render(shape: some Drawable) {
// drawWithAnimation 是静态调度(编译器知道具体类型)
shape.drawWithAnimation()
// draw 的调度取决于泛型参数是否被解析
}
func renderExistential(shape: Drawable) {
// 两个调用都可能走动态调度
shape.drawWithAnimation()
shape.draw()
}场景:理解协议方法声明的位置如何影响调度方式。坑点:把方法从 protocol requirement 移到 extension 会改变多态行为——子类型对该方法的覆盖将不再被调度到。
避免不必要的堆分配
// 可能触发堆分配的写法
func processData() -> () -> Void {
let largeData = LargeBuffer() // 如果被闭包捕获
// 编译器分析 largeData 是否逃逸
// 如果逃逸,会在堆上分配
return {
// 闭包捕获了 largeData
largeData.process()
}
}
// 优化:避免逃逸
func processDataInPlace() {
var buffer = LargeBuffer()
// buffer 不逃逸,编译器可以放在 CallFrame 上
processSync(&buffer)
// 栈分配,零堆分配成本
}
// 另一个常见陷阱:Existential Container
func process(values: [any Drawable]) {
// `any Drawable` 使用 Existential Container
// 小类型:内联存储(3个word)
// 大类型:堆分配额外存储
for value in values {
value.draw() // 动态调度
}
}
// 优化:使用泛型参数
func process<T: Drawable>(values: [T]) {
// T 的具体类型在编译时已知
// 没有 Existential Container 的开销
for value in values {
value.draw() // 静态调度,可能被内联
}
}场景:减少热路径上的堆分配和动态调度。坑点:any 关键字显式引入 existential,而 some 关键字保留具体类型信息——在性能敏感的代码中优先用 some。
Copy-on-Write 的正确使用
// Swift 标准库的 Array 使用 CoW 优化
// 但自定义类型需要自己实现
struct CustomBuffer {
private var _storage: Storage
private final class Storage {
var data: [UInt8]
init(data: [UInt8]) { self.data = data }
}
init(data: [UInt8]) {
_storage = Storage(data: data)
}
// mutating 方法中检查引用计数
mutating func append(_ byte: UInt8) {
// 如果引用计数 > 1,创建独立副本
if !isKnownUniquelyReferenced(&_storage) {
_storage = Storage(data: _storage.data)
}
_storage.data.append(byte)
}
// 只读操作不需要拷贝
func read(at index: Int) -> UInt8 {
_storage.data[index] // 共享同一份存储
}
}场景:自定义值类型需要高效地共享数据。坑点:isKnownUniquelyReferenced 只对 class 类型有效,如果你的 Storage 内部还有嵌套的引用类型,需要递归检查。
最佳实践
- 定期监控性能:不要等到出现性能问题才测量。自动化性能测试到开发流程中,捕获回归。
- 区分 protocol requirement 和 extension method:requirement 用动态调度,extension 用静态调度。性能关键路径上尽量用 extension method,但要理解语义变化。
- 优先使用
some而非any:some保留具体类型信息,允许编译器优化;any引入 existential container,产生额外开销。 - 关注值是否逃逸:不逃逸的值可以放在 CallFrame 上(栈分配,几乎免费),逃逸的值需要堆分配。闭包捕获是最常见的逃逸原因。
- 相信优化器但验证它:Swift 优化器很强,但它的能力受限于你写代码的方式。用 Instruments 验证关键路径是否被正确优化。
还有什么值得关注
- 泛型特化(Generic Specialization)能让泛型代码达到手写特化版本的性能,前提是编译器能看到具体类型的定义。
- 拷贝和销毁的成本在持有引用计数的类型(class 实例、closure)上特别明显——每次拷贝和销毁都涉及引用计数的原子操作。
- Swift 的编译器优化管道有多个层级,Debug 模式下的性能不能代表 Release 模式的表现。