自定义设备端语音识别:语言模型定制化
Customize on-device speech recognition
2023年6月5日
一句话判断
iOS 17 的 Speech 框架允许你定制语言模型,让你的 App 里的专业术语(象棋走法、药名、人名)不再被误识别。
这场 Session 讲了什么
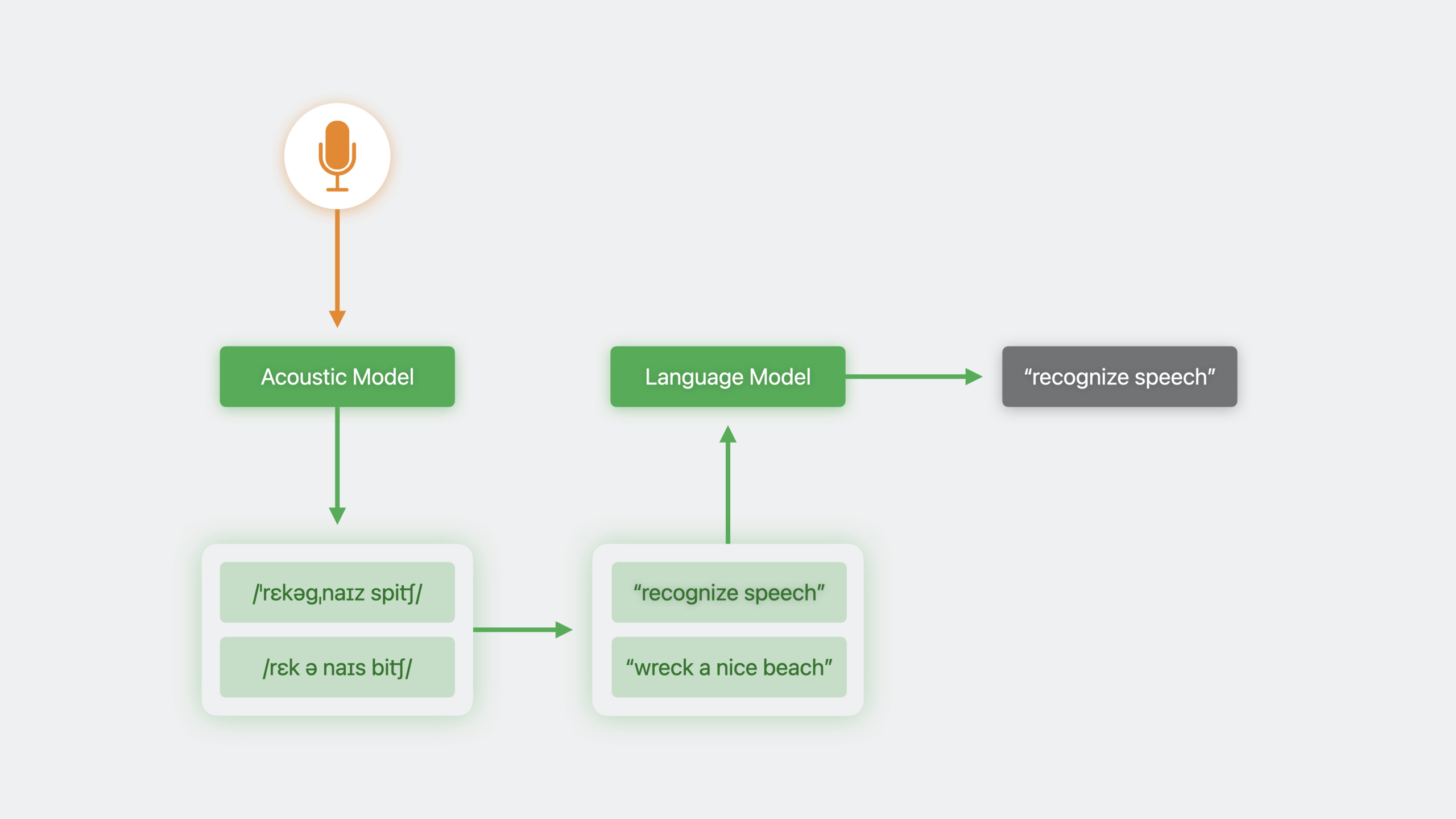
Ethan 从 Siri 理解团队出发,讲解了 iOS 17 中 Speech 框架的语言模型定制化能力:
问题背景。语音识别依赖语言模型来从多个候选转录中选出最可能的句子。但通用语言模型对所有 App 一视同仁,当你的 App 使用领域专业词汇时,识别准确率会大幅下降。Ethan 用象棋 App 做例子:“Play the Albin counter gambit”被误识别为音乐请求,因为通用模型更熟悉”Play the album…”的句式。
训练数据构建。新的 SFLanguageModel 类用 result builder DSL 构建训练数据。支持三种方式:精确短语(PhraseCount)、模板生成(将多个词类组合成模式,批量生成样本)、运行时动态数据(基于用户的使用习惯或通讯录人名)。可以为术语定义自定义发音(X-SAMPA 格式)。
部署流程。调用 prepareCustomLanguageModel 将训练数据编译为优化后的模型文件。这个过程有显著延迟,建议在后台线程执行,用加载界面遮盖。识别请求必须强制在设备端运行(requiresOnDeviceRecognition = true),否则定制不会生效。
隐私保护。定制数据不离开设备,所有定制化请求都在本地处理。适合通讯录人名、通话记录频率等隐私敏感数据。
值得深挖的点
训练数据预算。系统能接受的训练数据有限,你需要权衡各个短语的权重。用 PhraseCount 的 count 参数来控制权重——重要的短语给更高的 count。
模板生成的威力。象棋走法可以用”棋子+位置+王翼/后翼+数字”的模式自动生成所有可能的走法。10,000 个样本均匀分配到所有组合,比手动列举每个走法高效得多。
运行时训练的应用。通讯 App 可以根据通话频率来 boost 联系人名字的识别率;学习 App 可以重点训练用户正在学习的词汇。数据始终留在设备上。
代码片段
// 构建语言模型训练数据
let trainingData = SFLanguageModel {
// 精确短语,count 控制权重
PhraseCount("Play the Albin counter gambit", count: 10)
PhraseCount("Play the Winawer variation", count: 10)
// 自定义发音(X-SAMPA 格式)
PhraseCount("Winawer", count: 5, pronunciation: "wInAWEr")
// 模板:自动生成大量组合样本
Template(["King", "Queen", "Rook", "Bishop", "Knight", "Pawn"],
[" to "],
["kingside", "queenside"],
count: 10000)
// 生成: "King to kingside", "Queen to queenside" 等
}// 部署和使用定制模型
// 1. 编译训练数据(有延迟,放后台)
let url = try await prepareCustomLanguageModel(
trainingData,
identifier: "chess-moves",
locale: Locale(identifier: "en_US")
)
// 2. 创建识别请求并绑定模型
let request = SFSpeechAudioBufferRecognitionRequest()
request.requiresOnDeviceRecognition = true // 必须!否则定制不生效
request.customizedLanguageModel = url
// 3. 运行识别
let recognizer = SFSpeechRecognizer()
let task = recognizer?.recognitionTask(with: request) { result, error in
// 处理识别结果
}最佳实践
- 实验频次要高——你会惊讶于识别器的基础能力和改进速度。
- 用模板而非手动列举来覆盖组合空间大的词汇。
prepareCustomLanguageModel的延迟不可忽略,用加载 UI 遮盖。- 识别请求必须设置
requiresOnDeviceRecognition = true。 - 多语言场景用
NSLocalizedString管理不同 locale 的训练数据。
还有什么值得关注
- X-SAMPA 是一套标准的音标编码系统,每个 locale 支持的符号子集不同,查文档确认
- 医疗、法律、音乐等专业领域是语言模型定制的天然场景
- 通讯录人名、通话频率等隐私数据只在设备端使用,不会上传
- 象棋 App 的例子非常直观,可以作为教程模板