System & Services 进阶 20m
探索 Natural Language 多语言模型
Explore Natural Language multilingual models
2023年6月5日
一句话判断
BERT 嵌入来了,Natural Language 框架一次性支持 27 种语言,多语言文本分类从此变得简单。
这场 Session 讲了什么
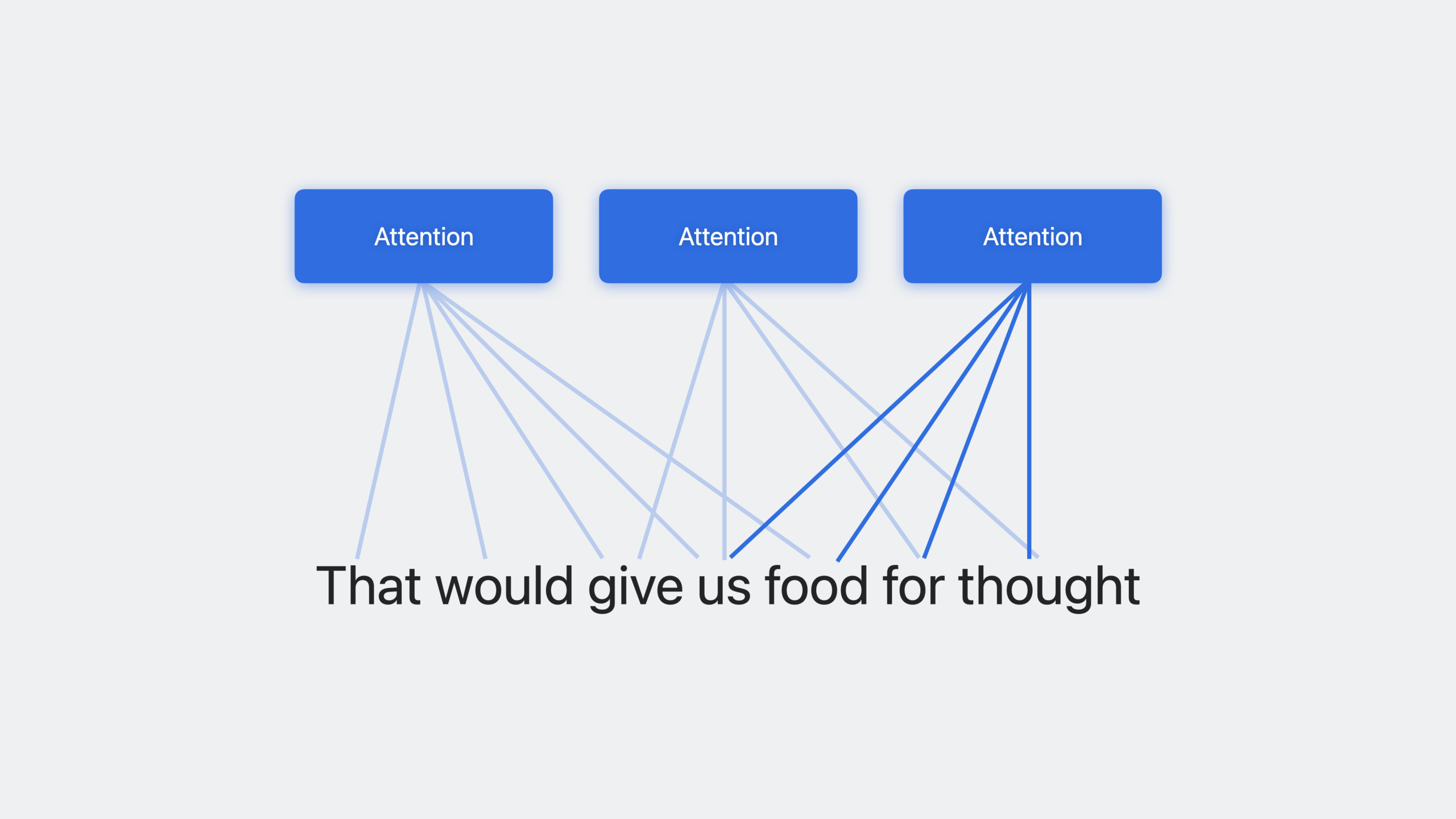
Natural Language 框架今年引入了基于 Transformer 的上下文嵌入——具体来说是 BERT(Bidirectional Encoder Representations from Transformers)嵌入。这些嵌入模型使用遮蔽语言模型的训练方式,基于多头自注意力机制,能够同时考虑文本中不同部分的权重。
多语言模型是最大的亮点。三个模型分别覆盖拉丁文字语言、西里尔文字语言和中文/日文/韩文,总共支持 27 种语言。由于语言间的相似性,数据有协同效应——为一种语言提供训练数据可以帮助其他语言。
在 Create ML 中训练多语言分类模型非常简单。选择 BERT 嵌入作为算法,指定文字系统,提供多语言训练数据,就可以训练出一个能处理多种语言的分类器。Session 演示了用英语、意大利语、德语和西班牙语训练的消息分类器,甚至能分类训练数据中没有的法语文本。
值得深挖的点
嵌入的演进反映了 NLP 领域的发展:从正字法特征到静态词嵌入(Word2Vec、GloVe),到动态上下文嵌入(ELMo),再到基于 Transformer 的嵌入(BERT)。每一步都在更好地捕捉语言的语义信息。
BERT 嵌入可以直接在代码中使用。通过 NLModel 和 Natural Language 框架的 API,你可以获取句子或文档级别的嵌入向量,用于自定义的相似度计算、聚类或其他下游任务。
代码片段
// 使用 Natural Language 框架获取 BERT 嵌入
import NaturalLanguage
let embedding = NLEmbedding()
// 获取句子的嵌入向量
// 使用 NLModel 进行分类预测
if let model = try? NLModel(mlModel: myModel) {
let prediction = model.predictedLabel(for: "这是一条测试消息")
// 获取多语言文本的分类结果
}
// Create ML 中选择 BERT 算法训练
// 1. 准备多语言 JSON/CSV 训练数据
// 2. 选择 BERT embeddings 算法
// 3. 选择文字系统(Latin/CJK/Cyrillic)
// 4. 开始训练最佳实践
- 为每种目标语言都提供训练数据,不要依赖跨语言泛化
- 选择与目标语言匹配的文字系统模型
- BERT 嵌入适用于文本分类和词标注两种任务
- 利用协同效应——即使小语种只有少量数据也能获得不错效果
- 新字段在 Xcode 15 构建的 app 中可用,且大部分向前兼容
还有什么值得关注
- 参考 2019 和 2020 年的 NLP 相关 session 了解基础功能
- BERT 嵌入的强大编码能力适合多种下游任务
- 多语言模型减少了为每种语言单独训练的维护成本
WWDC 2023