扩展语音合成:个性化语音与自定义语音
Extend Speech Synthesis with personal and custom voices
2023年6月5日
一句话判断
如果你在做 TTS(文字转语音)相关的产品,这场 Session 提供的 Speech Synthesis Provider API 和 Personal Voice 功能值得仔细研究——前者让你能把自定义语音引擎接入系统级别,后者让用户用自己的声音进行语音合成。
这场 Session 讲了什么
Session 围绕三个主题展开:SSML 标准的介绍与应用、自定义语音合成器的实现方式、以及全新的 Personal Voice 功能。
SSML(Speech Synthesis Markup Language)是 W3C 的口语表示标准,用 XML 格式描述语音属性。你可以用 <break> 标签插入停顿,用 <prosody> 标签控制语速和音高。AVSpeechUtterance 直接支持 SSML 输入,这是苹果第一方合成器(包括 WebKit 中的 WebSpeech)的标准输入格式。
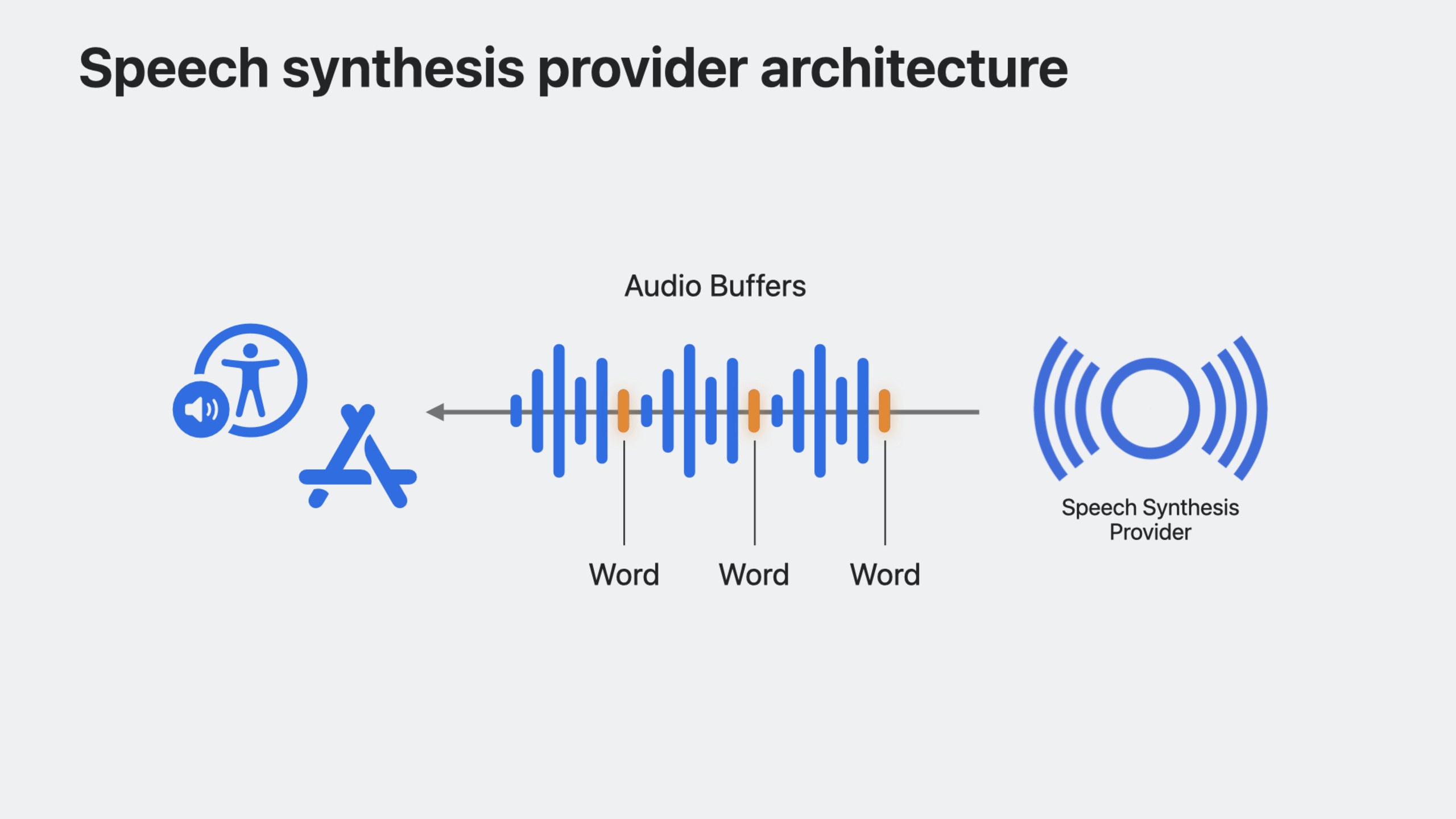
Speech Synthesis Provider 是今年的重头戏。它基于 Audio Unit Extension 架构,允许开发者将自己的语音合成引擎以 Extension 形式嵌入宿主 App。系统负责音频会话管理和播放,你的 Extension 只需关注 SSML 到音频的渲染。整个流程包括四个核心组件:speechVoices 属性声明可用语音、synthesizeSpeechRequest 接收合成请求、cancelSpeechRequest 取消当前请求、以及 renderBlock 填充音频帧。
Personal Voice 是一项辅助功能,让用户通过录制自己的声音来生成个性化合成语音。这对渐冻症等可能影响发声能力的用户意义重大——他们可以用自己的声音与外界交流。
值得深挖的点
语音购买与共享机制:Session 展示了一个语音商店的完整实现。通过 App Group 共享 UserDefaults,宿主 App 和 Extension 可以同步已购买的语音列表。购买完成后调用 AVSpeechSynthesisProviderVoice.updateSpeechVoices() 通知系统重建语音列表。这个设计模式在其他 Extension 场景中也很通用。
Audio Unit Extension 的渲染管线:renderBlock 是系统以指定 frameCount 调用的回调,你需要在 outputAudioBuffer 中填充对应数量的音频帧。渲染完成后设置 actionFlags = offlineUnitRenderAction_Complete 通知系统。这个底层音频处理模式对理解 iOS 音频架构很有帮助。
系统级集成:通过 Speech Synthesis Provider 注册的语音可以在 VoiceOver、系统设置以及任何使用 AVSpeechSynthesizer 的地方使用,真正做到了全系统可用。
代码片段
通过 App Group 共享已购语音列表:
// 宿主 App 和 Extension 使用同一个 suite name
let defaults = UserDefaults(suiteName: "group.com.example.synthesizer")
// 购买完成后更新语音列表
func purchaseVoice(_ voice: WWDCVoice) {
purchasedVoices.append(voice)
// 通知 Extension 语音列表已变化
updateDefaults()
// 通知系统重建语音列表
AVSpeechSynthesisProviderVoice.updateSpeechVoices()
}Extension 中声明可用语音并处理合成请求:
// 声明可用的语音列表
override var speechVoices: [AVSpeechSynthesisProviderVoice] {
let defaults = UserDefaults(suiteName: "group.com.example.synthesizer")
return defaults?.stringArray(forKey: "voices")?.compactMap { identifier in
AVSpeechSynthesisProviderVoice(name: identifier, identifier: identifier, locale: Locale(identifier: "en-US"))
} ?? []
}
// 接收合成请求
override func synthesizeSpeechRequest(_ request: AVSpeechSynthesisProviderRequest) {
// request 包含 SSML 和目标语音信息
currentBuffer = speechEngine.getAudioBuffer(voice: request.voice, ssml: request.ssml)
framePosition = 0
}最佳实践
- 监听
availableVoicesDidChangeNotification来响应系统语音列表的变化(用户删除或下载语音时触发) - 在宿主 App 中购买语音后,务必调用
updateSpeechVoices()让系统感知变化 - Extension 中的
synthesizeSpeechRequest收到请求后,先准备好音频缓冲区,再在renderBlock中逐帧填充 - SSML 是语音合成的标准输入格式,如果你的 TTS 引擎还不支持 SSML,建议优先适配
还有什么值得关注
- Personal Voice 功能对无障碍场景意义深远,值得关注其 API 设计思路
- 苹果在 WWDC 后续可能会开放更多 Personal Voice 的开发者接口
- Audio Unit Extension 架构的稳定性需要关注——Extension 进程崩溃不应影响宿主 App
- SSML 在 WebSpeech 中的应用方式可以作为 Web 端 TTS 的参考