使用 Metal Mesh 着色器变换几何体
Transform your geometry with Metal mesh shaders
2022年6月6日
一句话判断
Metal Mesh 着色器取代了传统顶点着色器阶段,用两个可编程阶段(Object Shader + Mesh Shader)实现了 GPU 端的几何体生成和处理——不再需要额外的计算通道和中间内存。
这场 Session 讲了什么
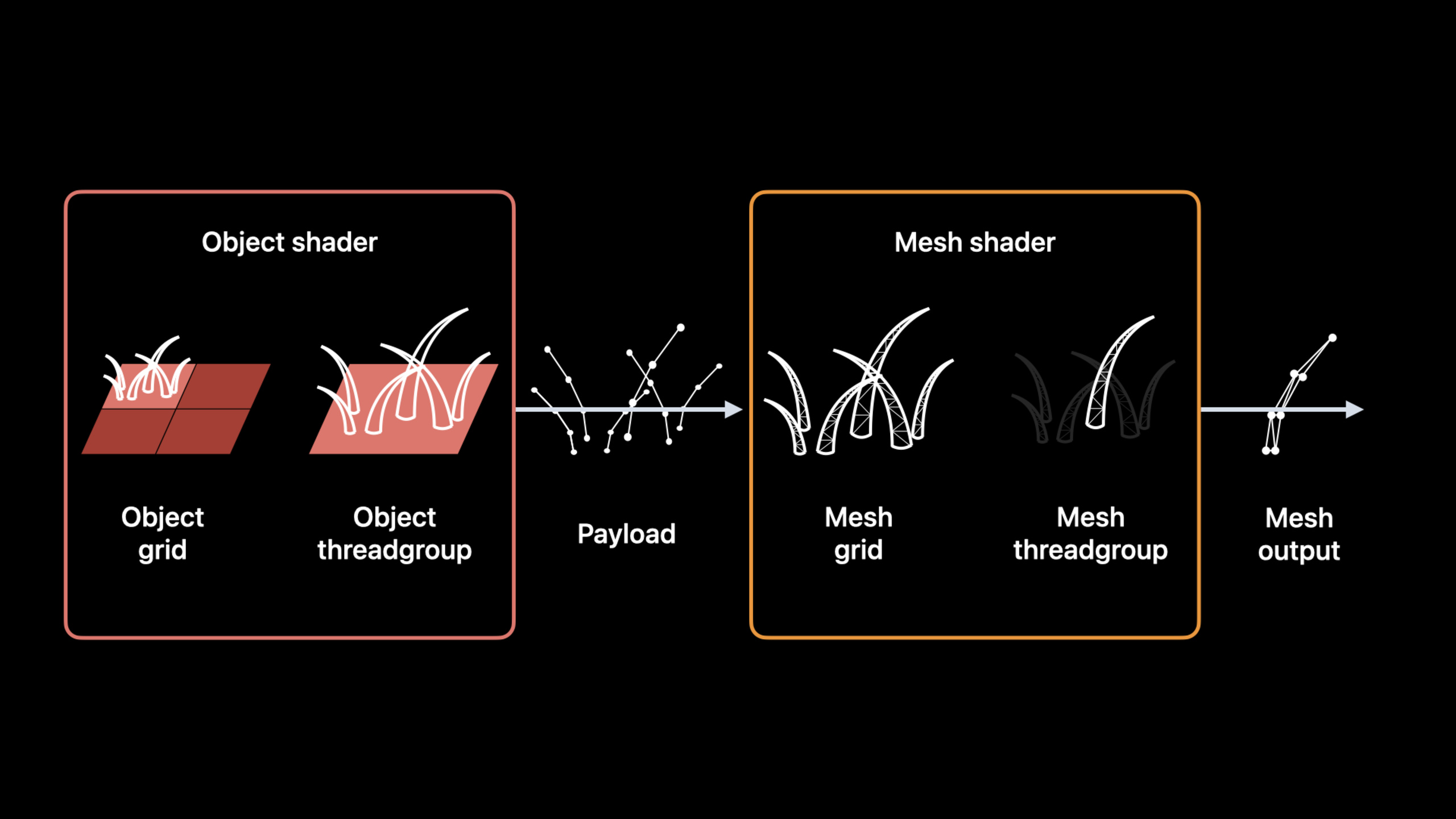
Metal 框架团队的 GPU 软件工程师 Andrei 介绍了 Metal 的全新 Mesh 着色器管线。传统渲染管线是 Vertex -> Rasterizer -> Fragment,新的 Mesh 管线将顶点阶段替换为两个可编程阶段:Object Shader 和 Mesh Shader。
Session 重点讲解了两个应用场景:程序化几何体生成(以毛发渲染为例)和 GPU 驱动的 Meshlet 剔除。前者展示了 Mesh 着色器如何消除传统方案中的计算通道和中间内存分配;后者展示了如何利用 Object Shader 的灵活性实现高效的 GPU 端几何体剔除。
Mesh 着色器与传统 draw call 使用相同类型的渲染命令编码器,可以混合使用。
值得深挖的点
Object Shader 和 Mesh Shader 的分工。 Object Shader 处理”对象”——一个抽象概念,可以是场景模型、模型的一部分、或空间中的一个区域。它计算并向 Mesh Shader 传递 Payload 数据。Mesh Shader 使用这些数据生成几何体,直接发送给光栅化器。每个 Object 线程组可以程序化地定义要启动的 Mesh Grid 大小。
消除中间内存分配。 传统方案中,程序化几何体需要先用计算通道生成几何体到设备内存,再用渲染通道读取。Mesh 着色器让程序化几何体只存在于 draw call 内部,直接流水线送到光栅化器,不需要分配额外的设备内存。对于间接绘制或高扩展因子的情况,这节省了大量难以预测的内存。
毛发渲染的工作方式。 以平面生成毛发为例:平面被分割为瓦片,每个瓦片对应一个 Object 线程组。Object 线程组计算每个毛发束的控制点(Payload),然后启动 Mesh Grid,每个 Mesh 线程组代表一根毛发。每个线程组可以生成不同大小的 Mesh Grid,实现了细节层次(LOD)控制。
Meshlet 剔除的 GPU 驱动方案。 利用 Object Shader 的灵活性,可以将模型的 meshlet 作为 Object 处理,在 GPU 端直接进行视锥剔除和遮挡剔除。被剔除的 meshlet 只需设置 Mesh Grid 大小为零即可,不会产生任何渲染开销。
代码片段
// Metal Mesh 着色器 - Object Shader(毛发渲染示例)
#include <metal_stdlib>
using namespace metal;
struct Payload {
float3 controlPoints[MAX_STRANDS]; // 曲线控制点
};
// Object Shader:处理每个瓦片,计算毛发参数
[[object]]
void objectShader(
object_data Payload& outputPayload [[payload]],
uint3 gid [[threadgroup_position_in_grid]],
uint3 lid [[thread_position_in_threadgroup]]
) {
// 计算这个瓦片需要生成的毛发束数
int strandCount = calculateStrandCount(gid.xy);
// 设置 Mesh Grid 大小(每个毛发束一个 Mesh 线程组)
mesh_grid_properties mgp;
mgp.set_threadgroups_per_grid(uint3(strandCount, 1, 1));
// 生成 Payload 数据(毛发控制点)
for (int i = 0; i < strandCount; i++) {
if (lid.x == 0) {
outputPayload.controlPoints[i] = computeControlPoints(gid.xy, i);
}
}
}
// Mesh Shader:生成单根毛发的几何体
[[mesh]]
void meshShader(
metal::mesh<float, uint, 4, 16, topology::triangle> outMesh,
const Payload payload [[payload]],
uint3 gid [[threadgroup_position_in_grid]],
uint3 lid [[thread_position_in_threadgroup]]
) {
// 使用 Payload 中的控制点生成毛发几何体
float3 controlPoint = payload.controlPoints[gid.x];
// 输出顶点和图元数据
outMesh.vertices[lid.x].position = computePosition(controlPoint, lid.x);
outMesh.primitives[lid.x] = computePrimitive(lid.x);
outMesh.set_primitive_count(16);
}// 配置 Mesh 渲染管线
let pipelineDescriptor = MTLMeshRenderPipelineDescriptor()
pipelineDescriptor.objectFunction = objectFunction
pipelineDescriptor.meshFunction = meshFunction
pipelineDescriptor.fragmentFunction = fragmentFunction
pipelineDescriptor.payloadLength = MemoryLayout<Payload>.size
pipelineDescriptor.maxTotalThreadgroupsPerMeshGrid = 64
pipelineDescriptor.colorAttachments[0].pixelFormat = .bgra8Unorm
let pipelineState = try device.makeMeshRenderPipelineState(descriptor: pipelineDescriptor)最佳实践
- Mesh 着色器适合程序化几何体生成、GPU 驱动的几何体剔除、自定义几何体输入(如压缩顶点流)
- Mesh draw call 和传统 draw call 可以混合使用,不需要一次性迁移
- Object 线程组可以程序化定义 Mesh Grid 大小,利用这种灵活性实现 LOD 和剔除
- Payload 数据完全由你定义,根据需要传递控制点、变换矩阵或其他中间数据
- 设置合理的
maxTotalThreadgroupsPerMeshGrid和payloadLength来优化 GPU 资源分配 - 对于 meshlet 剔除场景,将剔除逻辑放在 Object Shader 中,被剔除的对象设置 Mesh Grid 为零
还有什么值得关注
- Mesh 着色器目前需要 Apple Silicon 或特定 GPU 支持
- 传统的顶点/片段管线仍然有效,Mesh 着色器是可选的高级功能
- Session 还提到了 meshlet 的数据组织方式,对理解现代 GPU 几何体处理有帮助
- 配套观看其他 Metal 相关 Session 了解渲染管线的完整更新