在 Apple GPU 之间扩展计算工作负载
Scale compute workloads across Apple GPUs
2022年6月6日
一句话判断
如果你的 GPU 计算任务在 M1 上跑得不错但到 M1 Ultra 就看不到线性提升,这场 Session 提供了从工作分布、CPU/GPU 同步、原子操作到内存布局的系统性优化指南。
这场 Session 讲了什么
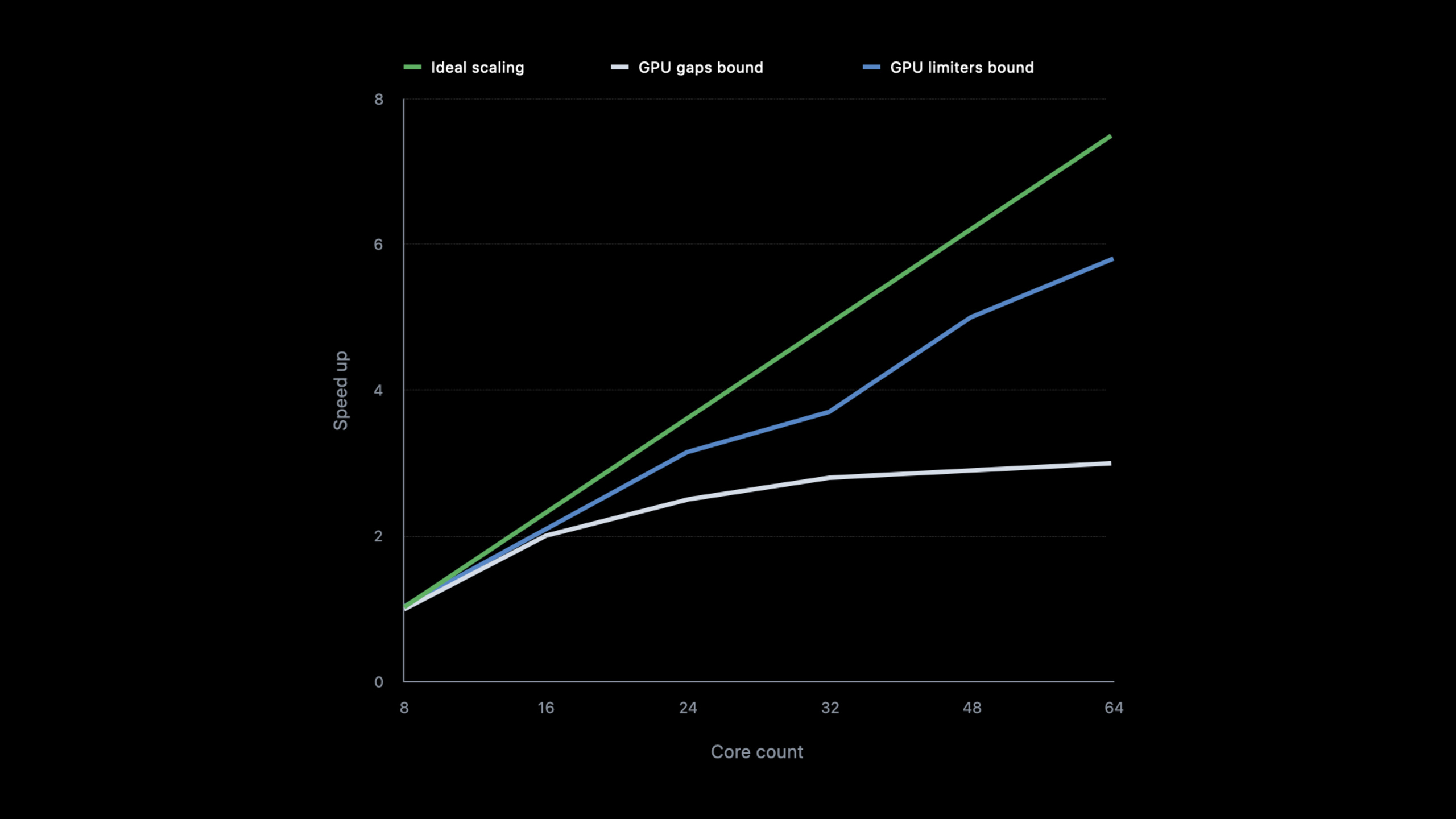
GPU 软件工程团队的 Marco Giordano 讲解了如何在 Apple M1 GPU 家族(8 核到 64 核)上实现接近线性的计算扩展。
核心概念:理想扩展是 GPU 核心数翻倍性能也翻倍,但现实中常见的三种问题是——GPU 时间线出现空闲间隙(idle gaps)、遇到计算或带宽瓶颈导致扩展曲线出现平台期、工作分布不均匀导致部分核心闲置。
优化分为两大部分:减少 GPU 空闲(优化工作分布、消除 CPU/GPU 同步瓶颈、注意原子操作开销)和突破 GPU 瓶颈(调整 compute grid 形状、优化内存布局)。以 Blender Cycles 渲染器为真实案例展示了优化过程。
值得深挖的点
CPU/GPU 同步是扩展杀手。 用 waitUntilCompleted 同步等待 GPU 完成意味着 CPU 和 GPU 无法并行。在 8 核 GPU 上可能不明显,但在 64 核上 GPU 跑得快了 CPU 端的串行时间占比就更大,扩展效率急剧下降。M1 Pro 的实测显示,去掉同步后扩展效率大幅改善。
工作分布的经验法则。 每个_shader core_需要 1K-2K 并发线程才能达到良好占用率。以 M1 Ultra(64 核)为例,至少需要约 64K-128K 并发线程。如果 threadgroup 太少或太大,GPU 核心分配不均匀。
Threadgroup 大小影响分布均匀性。 小 threadgroup 让 GPU 调度器有更多分配选择,大 threadgroup 可能导致某些核心负载过重。建议使用 SIMD width(32)的最小倍数。
代码片段
// 计算是否足够的线程来饱和 GPU
let gpuCores = device.presentsWithTransaction // 查询 GPU 核心数
let simdWidth = pipelineState.threadExecutionWidth // 始终为 32
// 经验法则:每个核心 1K-2K 并发线程
let minThreadsPerCore = 1024
let totalMinThreads = gpuCoreCount * minThreadsPerCore
// 选择合适的 threadgroup 大小(SIMD width 的最小倍数)
let threadgroupSize = MTLSize(width: simdWidth * 4, height: 1, depth: 1)
// 128 threads per threadgroup = 4 个 SIMD groups// 避免 CPU/GPU 同步——使用 Shared Event 替代 waitUntilCompleted
// 不好的做法:
// commandBuffer.commit()
// commandBuffer.waitUntilCompleted() // 阻塞 CPU!
// 好的做法:
let sharedEvent = device.makeSharedEvent()!
commandBuffer.signalEvent(sharedEvent, value: 1)
commandBuffer.commit()
// CPU 可以继续做其他工作
// 当需要结果时检查 event 状态最佳实践
- 用 Instruments GPU Tools 检查 GPU 时间线。 看 GPU track 是否有空闲间隙,空闲就是浪费。
- 保持 1K-2K 并发线程/核心。 用这个经验值验证你的 dispatch 尺寸是否足够。
- 尽量消除
waitUntilCompleted调用。 用 Shared Event 或 pipeline more work 来减少 CPU/GPU 串行。 - 优先考虑 MPS/MPSGraph。 如果你能用它们的原语,Apple 已经确保每个 kernel 在所有硬件上都跑得很好。
还有什么值得关注
- Blender Cycles 的优化案例展示了如何通过调整 tile 大小和内存布局从平台期恢复到线性扩展
- Xcode 14 新增了 max theoretical occupancy 指标,帮助诊断占用率问题
- 推荐观看 “Metal Compute on MacBook Pro” Tech Talk 了解更多占用率诊断技巧
- 原子操作在多核心场景下的竞争开销可能成为瓶颈,考虑用 local reduction 替代