Core Data 与 CloudKit 性能优化
Optimize your use of Core Data and CloudKit
2022年6月6日
一句话判断
Core Data + CloudKit 的同步性能终于有了系统级的优化指南——批量操作、分区策略、store 描述配置,照着做能把同步延迟从”几十秒”降到”几秒”。
这场 Session 讲了什么
这场 Session 针对使用 NSPersistentCloudKitContainer 的开发者,讲了如何优化 Core Data 和 CloudKit 之间的同步性能。如果你只是本地用 Core Data,这场 Session 和你关系不大。但如果你的 App 用了 CloudKit 同步,这里有几个关键优化点能显著改善用户体验。
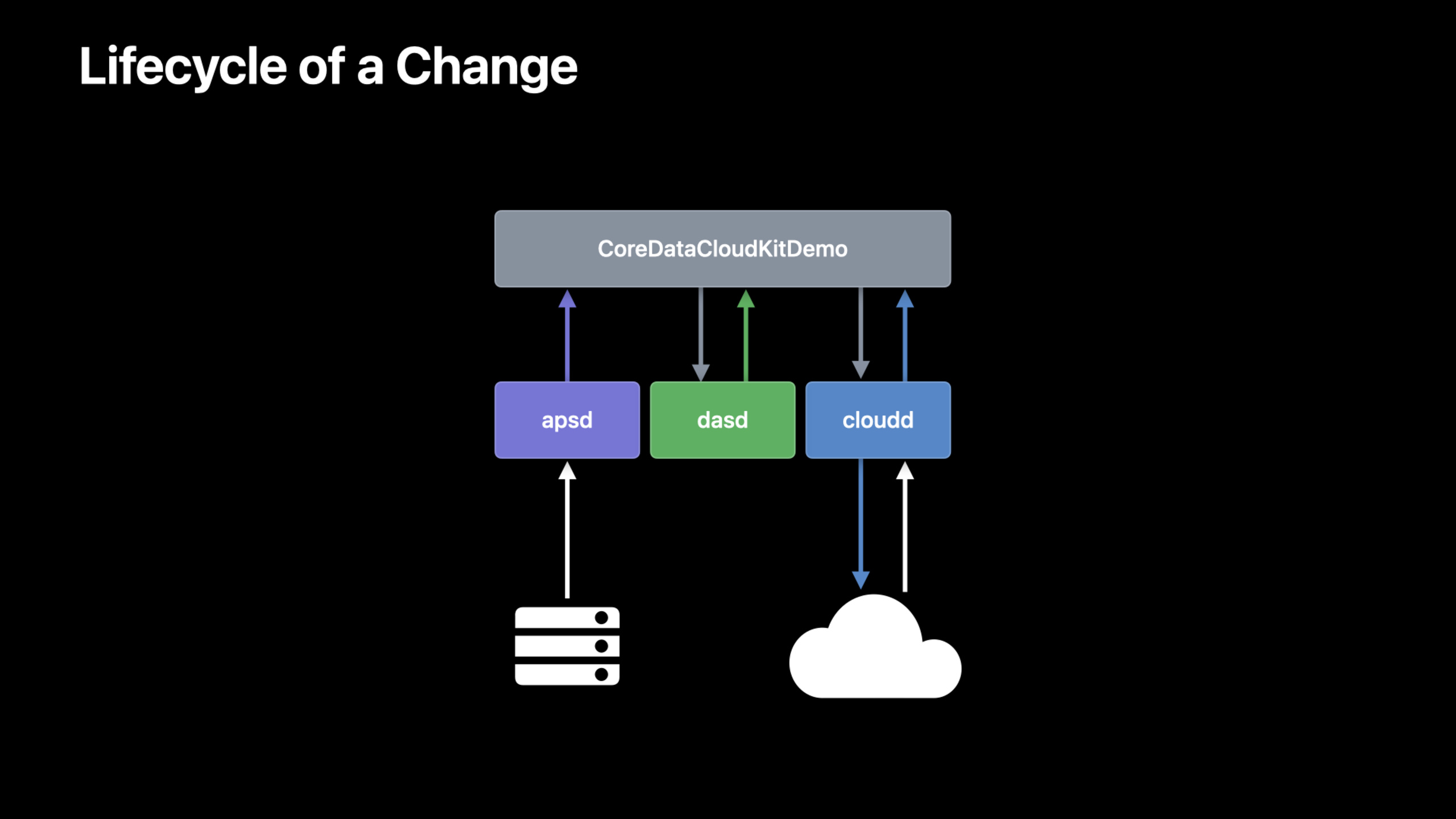
同步架构回顾。 NSPersistentCloudKitKitContainer 在本地 Core Data store 和 CloudKit database 之间维护一个同步引擎。同步引擎负责:检测本地变更 -> 生成 CKRecord -> 上传到 CloudKit -> 下载远端变更 -> 写入本地 store。整个过程是自动的,但有很多细节可以调优。
Store 描述(Store Description)配置。 NSPersistentCloudKitContainer 允许你为不同的 store 配置不同的同步行为。比如你可以创建两个 store:一个私有数据库 store 用于用户私有数据,一个共享数据库 store 用于协作数据。每个 store 可以独立配置同步频率和冲突解决策略。
批量操作。 这是性能优化最关键的一环。之前很多开发者习惯一条一条地 save record——每条 record 触发一次同步。正确的做法是用 NSBatchInsertRequest 或 NSBatchUpdateRequest 来批量操作。批量操作在 SQL 层面直接执行,不需要加载 NSManagedObject 到内存,速度更快,内存占用更小。对于 CloudKit 同步来说,批量操作会合并成更少的 CKRecord 操作,减少网络请求次数。
分区(Zone)策略。 CloudKit 使用 zone 来组织数据。默认情况下所有数据在一个 zone 里,但你可以用 CKRecordZone 来分区。合理的分区策略能减少同步冲突和提高查询性能。比如按”项目”或”日期”分区——用户操作一个项目时只需要同步那个项目的 zone,不需要同步整个数据库。
冲突解决。 当同一条 record 在多个设备上被同时修改时,CloudKit 会产生冲突。默认的冲突解决策略是”最后一个写入获胜”(last write wins),基于 modification date。如果你的 App 需要更复杂的冲突解决逻辑(比如合并字段级别的变更),可以实现自定义的 NSMergePolicy。
后台同步。 NSPersistentCloudKitContainer 支持在后台自动同步——即使 App 没有在前台运行,系统也会定期同步数据。你可以通过 NSPersistentStoreDescription 的 cloudKitContainerOptions 来配置自动同步行为。
值得深挖的点
批量操作对 CloudKit 同步的影响。 NSBatchInsertRequest 和 NSBatchUpdateRequest 在 Core Data 层面绕过了 NSManagedObject 的上下文,直接操作 SQLite。这意味着同步引擎检测变更的方式不同——它通过比较 SQLite 的 transaction log 来检测批量操作的变更。对于大量数据的初始导入(比如从服务器拉取 1000 条 record 并写入 Core Data),批量操作比逐条 insert 快 10 倍以上,而且只触发一次 CloudKit 同步。
Zone 分区和查询性能。 CloudKit 的查询是 zone 级别的——查询一个 zone 里的数据比跨 zone 查询快得多。如果你的数据有天然的分区维度(比如按用户、按项目),用 databaseScope 和自定义 zone 来分区。这样用户查询”我的项目数据”时,只需要扫描一个 zone,而不是整个数据库。
代码片段
配置多个 store 描述(私有 + 共享):
let container = NSPersistentCloudKitContainer(name: "MyApp")
// 私有数据库 store
let privateStoreDescription = NSPersistentStoreDescription()
privateStoreDescription.configuration = "Private"
privateStoreDescription.cloudKitContainerOptions = NSPersistentCloudKitContainerOptions(
containerIdentifier: "iCloud.com.example.myapp"
)
privateStoreDescription.cloudKitContainerOptions?.databaseScope = .private
// 共享数据库 store
let sharedStoreDescription = NSPersistentStoreDescription()
sharedStoreDescription.configuration = "Shared"
let sharedOptions = NSPersistentCloudKitContainerOptions(
containerIdentifier: "iCloud.com.example.myapp"
)
sharedOptions.databaseScope = .shared
sharedStoreDescription.cloudKitContainerOptions = sharedOptions
container.persistentStoreDescriptions = [privateStoreDescription, sharedStoreDescription]使用批量插入替代逐条创建:
// 旧方式:逐条创建(慢)
for item in items {
let record = MyRecord(context: context)
record.name = item.name
record.value = item.value
}
try context.save()
// 新方式:批量插入(快 10x+)
let batchInsert = NSBatchInsertRequest(entity: MyRecord.entity()) { index in
guard index < items.count else { return true } // 返回 true 表示结束
let item = items[index]
return [
"name": item.name,
"value": item.value,
"createdAt": Date()
]
}
batchInsert.resultType = .statusOnly
try container.viewContext.execute(batchInsert)最佳实践
初始数据导入一定要用批量操作。如果你在 App 首次启动时需要从服务器同步大量数据并写入 Core Data,不要用 NSManagedObject 逐条创建。用 NSBatchInsertRequest 把数据直接灌进 SQLite,然后把 CloudKit 同步交给后台处理。
给 Core Data 的 Configuration 做合理的划分。私有数据(用户设置、个人笔记)放一个 Configuration,共享数据(团队文档、协作内容)放另一个。每个 Configuration 对应不同的 CloudKit database scope,同步行为可以独立配置。
在 NSPersistentCloudKitContainer 的 eventChangedNotification 回调里监控同步状态。你不需要自己实现同步状态 UI——监听这个通知就能知道同步是进行中、成功还是失败了。在 UI 上给用户一个”正在同步”的指示器就够了。
还有什么值得关注
NSPersistentCloudKitContainer在 iOS 16 中对大文件(CKAsset)的同步做了优化,支持断点续传。- 如果你的 App 需要离线优先的体验,确保
NSPersistentStoreDescription的setOption(true, forKey: NSPersistentStoreRemoteChangeNotificationOption)已开启,这样远端变更到达时会收到通知。 - CloudKit 的每日 API 配额是有限的(免费用户 40 万次/天,付费用户更高)。批量操作和合理的 zone 分区能显著减少 API 调用次数。
- 测试同步时用两个不同的 iCloud 账号登录两台设备,不要在模拟器上测同步——模拟器的 CloudKit 行为和真机有差异。