Metal 光线追踪性能优化
Maximize your Metal ray tracing performance
2022年6月6日
一句话判断
Metal 3 给光线追踪加了 per-primitive data、heap 分配加速结构和间接命令缓冲支持,配合 Apple Silicon 上 2.3 倍的加速结构构建速度提升,终于让实时全局光照从 Demo 走向了产品。
这场 Session 讲了什么
这场 Session 深入讲解了 Metal 3 中光线追踪相关的性能优化手段。如果你去年已经在用 Metal ray tracing,今年这几项改进可以让你的渲染管线跑得更快、支持更大的场景。
Per-primitive data。 这是今年最重要的改动。之前的 alpha testing 交叉函数需要经过多层指针间接引用才能拿到纹理数据——先读 instance data,再读 material index,再读 material,最后采样纹理。现在你可以直接把纹理和 UV 坐标塞进 acceleration structure 的 per-primitive data 里,交叉函数只需要一次内存读取就能拿到所有需要的数据。Apple 自己的测试应用显示性能提升 10%-16%,场景越复杂提升越明显。
Buffers from intersection function tables。 之前交叉函数表的 buffer 只能在构建时静态绑定,现在可以动态设置了。这意味着你可以在运行时切换材质或纹理,不需要重建整个 intersection function table。
从间接命令缓冲发起 ray tracing。 Metal 3 允许你从 indirect command buffer 发起 ray query,这让你可以在 compute pass 里用 GPU 驱动的逻辑来决定何时、何地发射光线。对于延迟渲染器或者需要 GPU culling 的场景,这是一个非常实用的能力。
加速结构构建性能提升。 在 Apple Silicon 上,新的加速结构构建算法让构建速度提升了 2.3 倍,refit(更新已有加速结构)速度提升了 38%。这意味着动态场景中每帧重建加速结构的开销大幅降低,实时更新场景几何变得可行。
并行构建加速结构。 Metal 3 允许在同一个 command buffer 里并行构建多个 acceleration structure。对于大型场景(比如开放世界游戏),你可以把场景拆成多个子区域,并行构建各自的加速结构,然后合并成一个顶层加速结构。
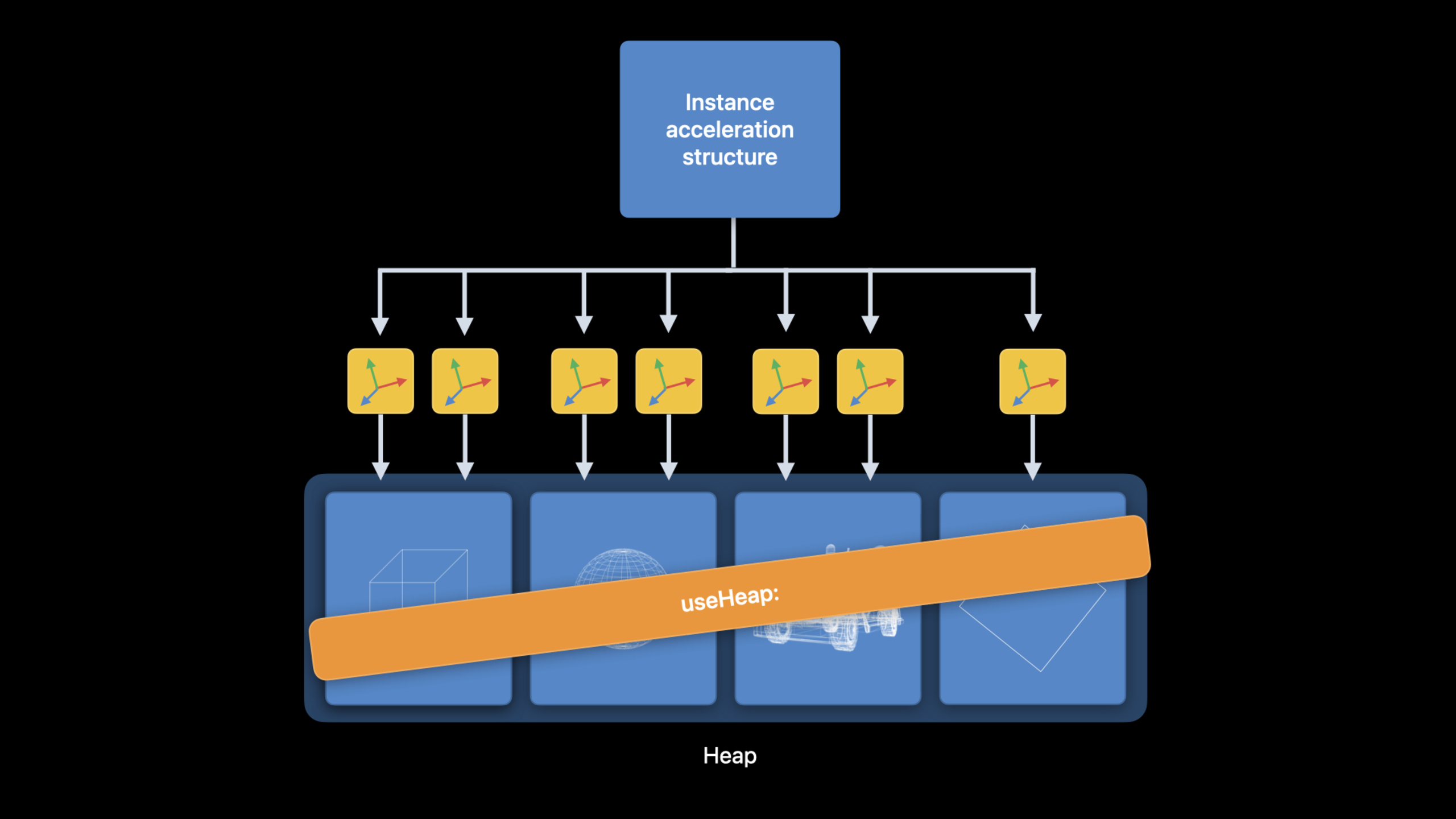
Heap 分配加速结构。 之前每帧渲染时,instance acceleration structure 需要为每个 primitive acceleration structure 调用 useResource:,场景一大可能要调几千次。把所有 primitive acceleration structure 分配到同一个 heap 之后,只需要调一次 useHeap: 就能让所有资源常驻 GPU。API 层面的改动很小(换个分配方式),但对大场景的性能影响可能很显著。
新的顶点格式和变换矩阵。 acceleration structure 的 geometry descriptor 新增了对 MTLDataType 的直接支持,你可以用更紧凑的顶点格式来减少内存占用。另外,instance descriptor 现在支持直接设置变换矩阵,不再需要手动把矩阵展开成列。
值得深挖的点
Per-primitive data 的内存布局。 per-primitive data 存储在 acceleration structure 内部,GPU 访问时缓存命中率极高。但这也意味着你需要在构建加速结构时就确定好数据内容,后续修改需要重建加速结构。对于静态场景这不是问题,但对于动态场景(比如角色动画),你可能需要把”频繁变化的数据”和”相对固定的数据”分开——固定的放 per-primitive data,动态的用传统 buffer binding。
Heap 分配是大规模场景的必选项。 当你的场景有上千个 mesh 时,useResource: 的调用开销会成为瓶颈。这不是”锦上添花”的优化,而是”不做就会卡”的硬性要求。Apple 的建议是:把所有 acceleration structure 放进同一个 heap,只在场景结构发生变化时才更新 heap。
代码片段
配置 per-primitive data:
// 创建带有 per-primitive data 的 geometry descriptor
let geometryDescriptor = MTLAccelerationStructureTriangleGeometryDescriptor()
geometryDescriptor.vertexBuffer = vertexBuffer
geometryDescriptor.vertexBufferOffset = 0
geometryDescriptor.triangleCount = triangleCount
// 设置 per-primitive data
geometryDescriptor.perPrimitiveDataBuffer = perPrimitiveDataBuffer
geometryDescriptor.perPrimitiveDataBufferOffset = 0
// 指定 stride,让系统知道每个 primitive 的数据有多大
geometryDescriptor.perPrimitiveDataStride = MemoryLayout<PerPrimitiveData>.stride在交叉函数中访问 per-primitive data:
// Metal Shading Language
struct PerPrimitiveData {
uint textureIndex;
float2 uvOffset;
};
intersection_function_table table;
// 交叉函数里直接读取 per-primitive data
intersection_result result = ...;
PerPrimitiveData data = result.get_primitive_data<PerPrimitiveData>();
texture2d<float, access::sample> tex = textures[data.textureIndex];
float2 uv = result.get_triangle_barycentric_coord() + data.uvOffset;使用 heap 分配加速结构:
// 创建 heap
let heapDescriptor = MTLHeapDescriptor()
heapDescriptor.size = totalAccelerationStructureSize
heapDescriptor.storageMode = .private
let heap = device.makeHeap(descriptor: heapDescriptor)!
// 从 heap 分配加速结构
let accelDescriptor = MTLAccelerationStructureDescriptor()
// ... 配置 descriptor
let accelerationStructure = heap.makeAccelerationStructure(
descriptor: accelDescriptor,
commandBuffer: commandBuffer
)
// 只需一次 useHeap 调用
renderEncoder.useHeap(heap)最佳实践
对于动态场景,优先使用 refit 而不是重建加速结构。refit 的开销只有完整重建的约 60%(现在又快了 38%),对于刚体运动和蒙皮动画来说精度已经足够。只有当场景拓扑结构发生变化(比如物体被摧毁)时才需要完整重建。
构建加速结构时尽量使用并行构建。把大型场景拆成多个子区域,用 MTLParallelRenderCommandEncoder 或多个 compute pass 并行构建各自的 BLAS(Bottom-Level Acceleration Structure),最后统一构建 TLAS(Top-Level Acceleration Structure)。
交叉函数尽量精简。per-primitive data 的引入让交叉函数的内存访问变得极其高效,但交叉函数本身还是在 ray tracing 管线的热路径上。避免在交叉函数里做复杂的逻辑判断或纹理采样——只做”命中还是没命中”的判断,材质计算放到 closest hit 函数里。
还有什么值得关注
- Xcode 14 的 Metal 工具链对 ray tracing 的调试支持大幅增强。Acceleration Structure Viewer 可以可视化你的加速结构,帮你发现 geometry 配置错误。
- 新的
MTLAccelerationStructureInstanceDescriptor支持直接设置变换矩阵(MTLMatrix4x4),不再需要手动转换成三列矩阵格式。代码可读性提升不小。 - 如果你在用 Metal Performance Shaders 的 ray tracing API,需要迁移到 Metal 3 的原生 API。MPS 版本的 ray tracing 已经进入维护模式,不会有新的功能更新。
- Apple Silicon 和 Intel GPU 的加速结构构建算法不同,性能数据不要跨平台对比。Apple Silicon 上的 2.3 倍提升在 Intel GPU 上可能看不到。