用 Metal 加速机器学习
Accelerate machine learning with Metal
2022年6月6日
一句话判断
PyTorch 官方 MPS 后端、TensorFlow 大 batch 支持和 MPS Graph 增强——在 Mac 上做 GPU 模型训练终于不再是二等公民体验了。
这场 Session 讲了什么
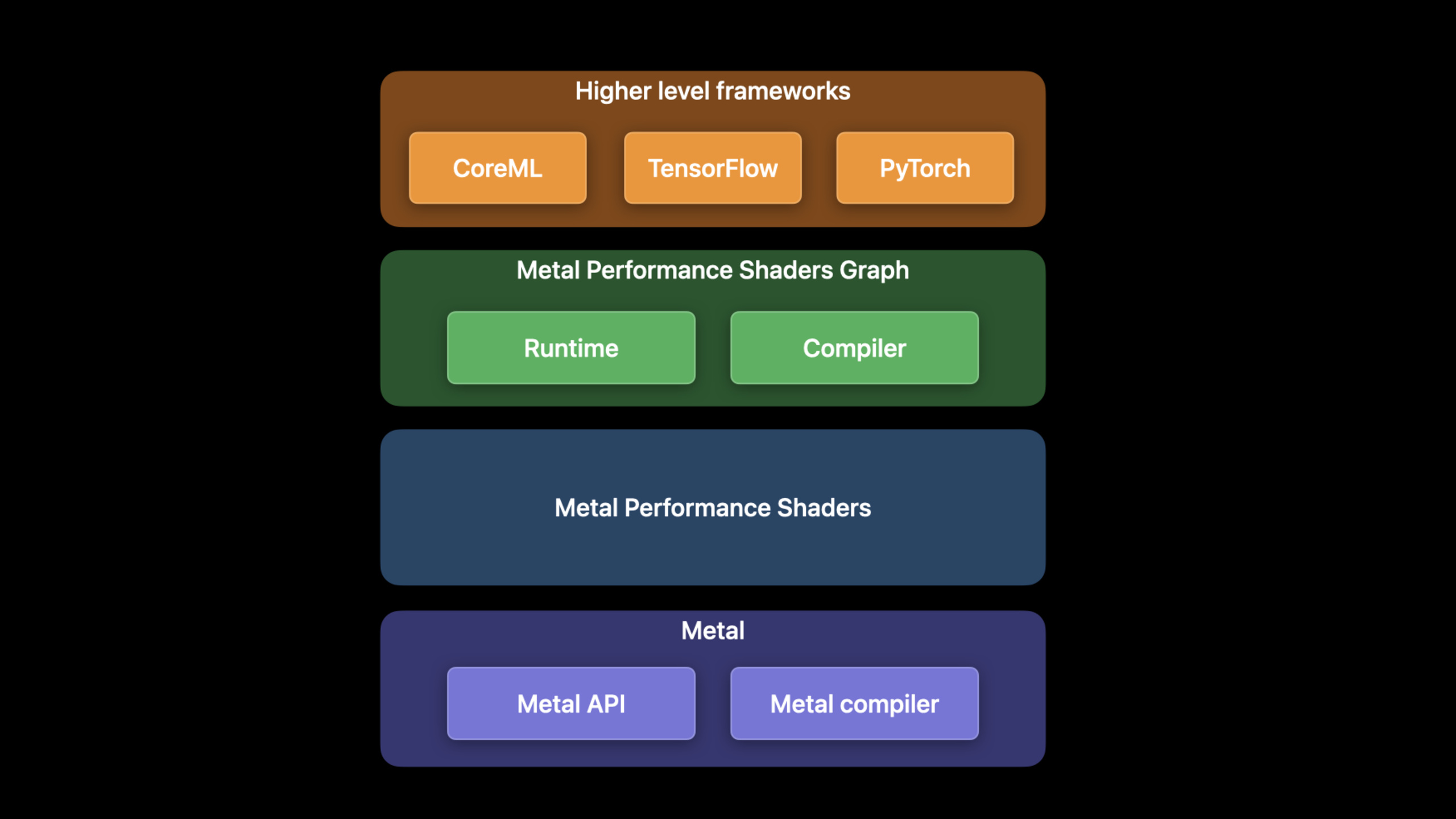
Apple 在 Metal Performance Shaders (MPS) 框架上持续投入,为三大机器学习生态提供 GPU 加速:
PyTorch MPS 后端:这是今年最大的消息。PyTorch 1.12 官方内置了 MPS 后端,开发者可以用三行代码把模型和输入搬到 Apple GPU 上。在 M1 Ultra 上,StyleTransfer 等常见网络训练速度平均提升 8.3 倍,最高达 20 倍。MPS 后端已合入 PyTorch 官方 GitHub 仓库。
TensorFlow Metal 增强和自定义算子:支持更大的 batch size(利用 Apple Silicon 统一内存架构)、新的 GPU 加速算子(argMin、pack、adaDelta 等),以及自定义算子的 Metal Stream 协议。统一内存让单台 Mac Studio 就能跑过去需要云端集群才能承载的大 batch 训练任务。
MPS Graph 更新:新增多维张量支持和更多计算图节点类型。
值得深挖的点
PyTorch MPS 后端的三行代码接入体现了 Apple 对开发者体验的重视。pip install torch,创建 mps device,然后用 .to(device) 把模型和数据搬过去——这对任何用过 PyTorch CUDA 后端的人来说都是零学习成本。MPS 后端调用 MPS Graph 和 MPS 的优化内核,同时使用 Metal 的 Command Queue 和同步原语。
统一内存架构的 ML 优势是一个容易被忽略但影响深远的特性。传统 GPU 架构中,大 batch 训练受限于显存大小。Apple Silicon 的统一内存意味着 batch size 只受系统总内存限制。一台 128GB 的 Mac Studio 可以跑的 batch size 超过很多独立 GPU 服务器。
TensorFlow 自定义算子的 Metal Stream 协议让不支持的算子也能上 GPU。Session 展示了一个使用自定义损失函数的卷积网络——如果损失函数只在 CPU 上运行,GPU 和 CPU 之间的同步开销会严重拖慢训练。通过 Metal Stream 协议把自定义算子编码到 GPU 命令缓冲区,消除了同步开销。
代码片段
PyTorch MPS 后端三步接入:
# 第一步:安装 PyTorch 1.12+
# pip install torch
# 第二步:创建 MPS device
import torch
if torch.backends.mps.is_available():
mps_device = torch.device("mps")
else:
mps_device = torch.device("cpu")
# 第三步:将模型和数据搬到 MPS device
import torchvision
model = torchvision.models.resnet50(pretrained=True).to(mps_device)
# 随机输入也搬到 MPS
input_tensor = torch.randn(1, 3, 224, 224).to(mps_device)
# 运行推理——自动在 Apple GPU 上执行
output = model(input_tensor)TensorFlow 自定义算子 Metal Stream:
# 自定义算子需要遵循 Metal Stream 协议
# Metal Stream 持有 MTLCommandBuffer 的引用
# 用于编码 GPU 操作
class CustomLossOp:
def compute(self, metal_stream, input_data):
# 1. 通过 metal_stream 获取 command buffer
# 2. 编码自定义 GPU kernel
# 3. 使用 metal_stream.commit() 提交
# 或 metal_stream.commitAndWait() 用于调试
passMPS 基础使用:
// MPS Graph 构建
let graph = MPSGraph()
let input = graph.placeholder(shape: [1, 3, 224, 224],
dataType: .float32)
// 在 GPU 上执行计算图
let results = graph.run(
feeds: [input: inputTensor],
targetTensors: [output],
targetOperations: nil
)最佳实践
- 用
to(device)统一管理设备:模型和数据都要搬到 MPS device,否则中间张量会在 CPU 上创建 - 大 batch 优先用 TensorFlow:统一内存架构下 batch size 可以设得比独立 GPU 更大
- 自定义算子用 Metal Stream 编码:避免 GPU-CPU 同步开销
- M1 Ultra 上训练最快:多 GPU core 提供更高并行度
- 用 commitAndWait 调试:序列化提交帮助你观察 GPU 执行顺序
还有什么值得关注
- MPSImageCanny 滤镜处理 4K 图片速度提升 8 倍,对图像分割应用很有用
- MPS 后端支持所有 Apple Silicon 设备,从 M1 到 M1 Ultra
- Core ML 和 TensorFlow 都基于 MPS Graph 构建,底层优化惠及所有上层框架
- 高级 ML 框架(如 Core ML)自动利用 MPS 加速,不需要手动管理