Core ML 性能优化:Float16 原生支持、新 Instrument 和权重压缩
Optimize your Core ML usage
2022年6月6日
一句话判断
Xcode 14 新增的 Core ML Performance Report 让你不用写一行代码就能看到模型在各设备上的预测时间和负载时间——这比之前写 prototype 手动 profile 要省力一个数量级。
这场 Session 讲了什么
Core ML 的使用流程可以分成三步:选模型、集成到 app、优化性能。今年的更新覆盖了全部三个阶段。
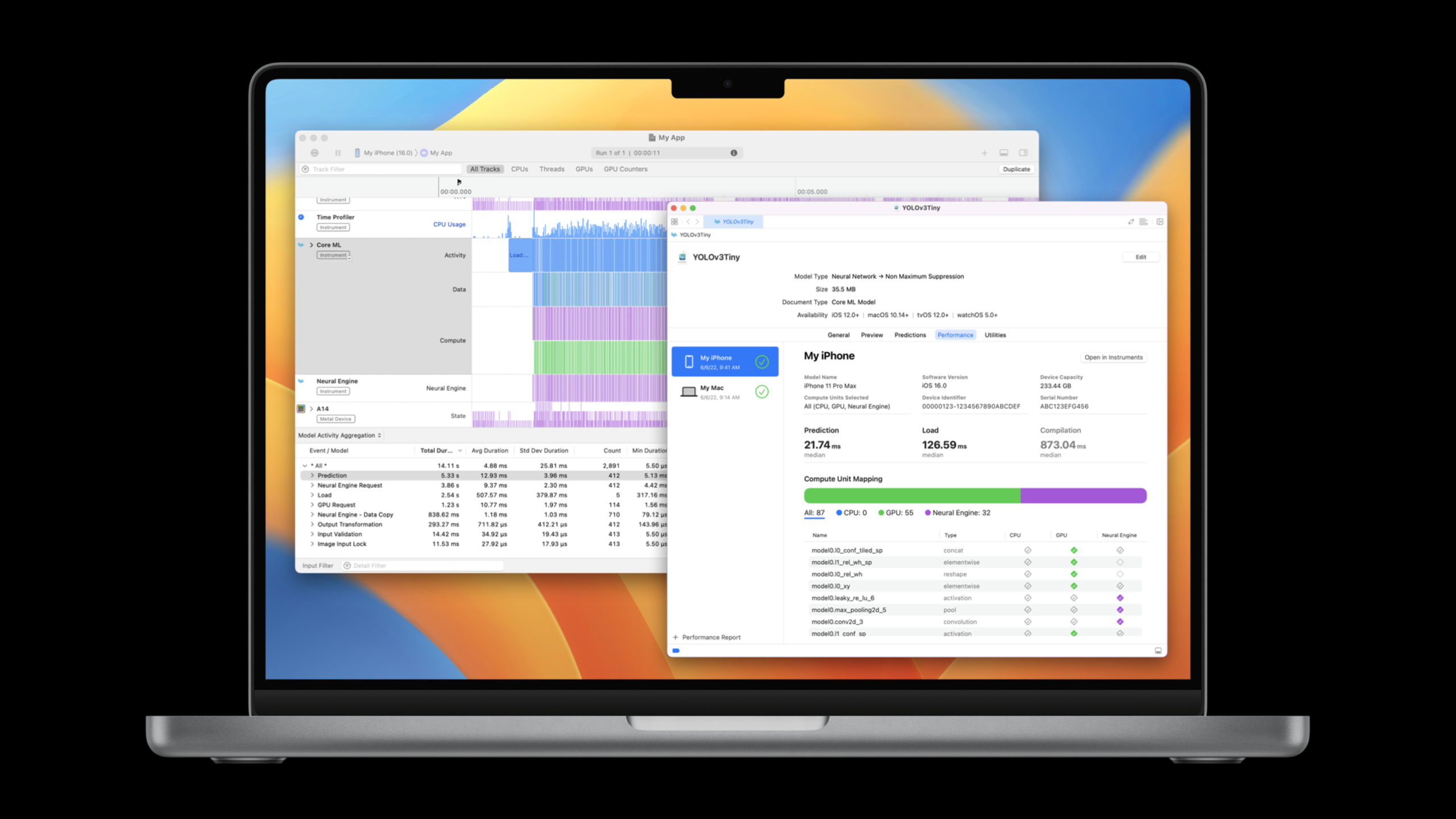
选模型阶段,Xcode 14 的 model viewer 新增了 Performance tab。你选择目标设备和 compute units,点击 Run Test,Xcode 会自动把模型发送到设备上编译、加载、多次运行预测,然后生成性能报告,显示中位数预测时间、加载时间和编译时间。对于神经网络模型,还会显示每一层跑在哪个计算单元上。
集成和优化阶段,新增了 Core ML Instrument。Session 演示了一个风格迁移 app 的调优过程:通过 Instrument 发现每次预测前都在重新加载模型(因为用了 computed property),改成 lazy var 后性能立刻提升。你还可以结合 GPU Instrument 和新的 Neural Engine Instrument 来看模型在不同计算单元上的执行时间线。
API 层面,iOS 16 新增了 Float16 原生支持——你的 app 可以直接把 Float16 的 CVPixelBuffer 喂给 Core ML,不需要再在 app 里做 8-bit 到 Float16 的转换。还有 output backing API 让你预分配输出 buffer,避免每次预测都创建新 buffer。
值得深挖的点
Float16 支持消除了一个隐藏的性能杀手。 Session 展示了一个很典型的场景:app 在 GPU 上做前后处理,数据是 Float16 精度。但模型要求 8-bit 灰度图输入,所以 app 要先把 Float16 转成 8-bit,然后 Core ML 内部又要把 8-bit 转回 Float16 才能在 Neural Engine 上跑。两次无意义的数据拷贝和转换。有了 Float16 原生支持,app 直接把 Float16 CVPixelBuffer 传给 Core ML,Instruments trace 里 Data lane 的数据转换操作直接消失。结合 IOSurface-backed buffer 和 unified memory,数据在不同计算单元间流转完全零拷贝。
新的 cpuAndNeuralEngine compute unit 选项。 之前你有 cpuOnly、cpuAndGPU、all 三种选择。现在新增 cpuAndNeuralEngine,告诉 Core ML 不要用 GPU。这在你 app 自己重度使用 GPU 时很有用——避免 Core ML 和你的渲染管线抢 GPU 资源。
代码片段
用 Float16 直接传入 Core ML,零拷贝:
// 之前:需要手动降精度
// let downcast = convertFloat16ToUInt8(inputBuffer) // 浪费
// let output = try model.prediction(image: downcast)
// let upcast = convertUInt8ToFloat16(output) // 又浪费
// iOS 16:直接传 Float16 CVPixelBuffer
let float16Input: CVPixelBuffer // OneComponent16Half 格式
let prediction = try model.prediction(image: float16Input)
// 返回的也是 OneComponent16Half CVPixelBuffer
// 不需要任何数据转换预分配输出 buffer:
// 创建可复用的输出 buffer
let outputBuffer = createOneComponent16HalfCVPixelBuffer()
// 设置到 prediction options
let options = MLPredictionOptions()
options.setOutputBacking(with: outputBuffer)
// 多次预测复用同一个 buffer
for frame in cameraFrames {
let result = try model.prediction(from: input, options: options)
// result 使用了你预分配的 buffer,没有额外的内存分配
}生成性能报告(Xcode 14):
// 在 Xcode 中双击 .mlmodel 文件
// 切换到 Performance tab
// 点击 + 选择目标设备(你的 iPhone)
// 选择 compute units(推荐 All 让 Core ML 自动优化)
// 点击 Run Test
// 结果示例:
// - 中位预测时间:22.19 ms → 约 45 FPS
// - 中位加载时间:400 ms
// - 编译时间:940 ms
// - 54 层跑在 GPU,32 层跑在 Neural Engine最佳实践
- 用 Performance Report 在开发早期就评估模型是否满足实时性要求,不要等到集成完才发现。
- 模型只加载一次,持在内存中。用 lazy var 或在合适的生命周期方法中初始化。
- 尽量用 IOSurface-backed CVPixelBuffer 作为输入输出,利用 unified memory 避免拷贝。
- 用 Float16 输入输出和 output backing 消除数据转换和内存分配开销。
- 你的 app 如果重度使用 GPU,把 Core ML 的 compute units 设为 cpuAndNeuralEngine。
还有什么值得关注
- 权重压缩现在支持 ML Program 模型类型,包括 quantize(16-bit/8-bit)、palettize(调色板)和 sparsify(稀疏化)。
- Core ML 模型现在可以包含在 Swift packages 中,Xcode 自动编译和代码生成。
- 新增内存中的模型编译和加载 API,支持自定义加密方案。