Machine Learning & AI 进阶 20m
用 Create ML Components 组合高级模型
Compose advanced models with Create ML Components
2022年6月6日
一句话判断
Create ML Components 的 Temporal Transformer 和增量训练让你用纯 Swift 构建视频动作识别和自定义声音分类器——从实验到部署全链路可控。
这场 Session 讲了什么
这是 Create ML Components 的进阶 Session。基础部分(Transformer、Estimator 的概念)在 “Get to know Create ML Components” 中介绍。本场聚焦两个高级主题:时序数据处理和增量训练。
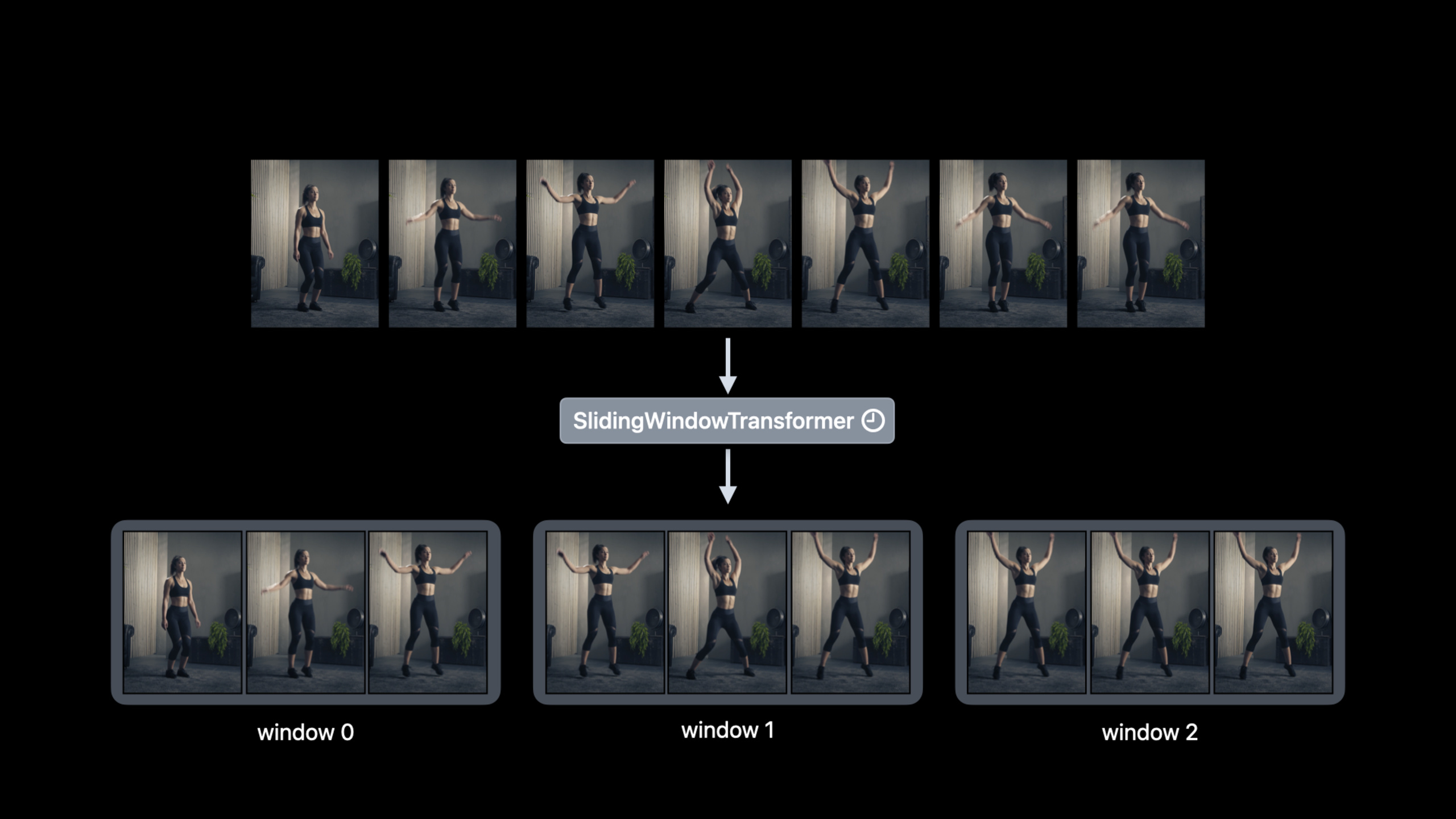
时序数据部分引入了 Temporal Transformer 概念——处理 AsyncSequence 输入并输出新 AsyncSequence 的变换器。Session 构建了一个动作重复计数器,组合了 Human Body Pose Extractor、Pose Selector、Sliding Window 和 Human Body Action Counter 四个组件。
增量训练部分展示了如何将声音分类器的特征提取和分类器训练解耦。预处理特征数据后,后续训练只需要处理新增数据,大幅缩短迭代时间。还支持 early stopping 和 checkpoint。
值得深挖的点
- Temporal Transformer 的组合能力:Pose Extractor(图像到姿态数组)+ Pose Selector(数组到单个姿态)+ Sliding Window(窗口化)+ Action Counter(计数)。每个组件职责单一,组合后的效果是完整的视频动作分析管线。
- 实时摄像头的应用:用
readCamera方法把摄像头帧作为 AsyncSequence 输入。调整 stride 参数可以控制输出频率——30fps 的摄像头设置 stride 为 15,每 0.5 秒输出一次计数更新。 - 增量训练的预处理分离:把特征提取(耗时)和分类器训练(快速)分开。新数据到来时只需要提取新数据的特征,然后和之前缓存的特征一起训练。这把小时级的重训练缩短到分钟级。
- AudioFeaturePrint 的窗口机制:它自带窗口化处理,自动把音频缓冲区分组后提取特征。你不需要额外加 Sliding Window。
代码片段
import CreateMLComponents
// 构建动作重复计数器
let actionCounter = HumanBodyPoseExtractor()
.appending(PoseSelector(strategy: .rightMostJointLocation))
.appending(SlidingWindow(length: 90, stride: 90))
.appending(HumanBodyActionCounter())
// 处理视频文件
let videoReader = VideoReader()
let frames = videoReader.read(url: videoURL)
for await count in actionCounter.applied(to: frames) {
print("当前动作重复次数: \(count)")
}
// 实时摄像头计数(stride 调小以获得更频繁的更新)
let cameraConfig = CameraConfiguration()
let liveActionCounter = HumanBodyPoseExtractor()
.appending(PoseSelector(strategy: .rightMostJointLocation))
.appending(SlidingWindow(length: 90, stride: 15))
.appending(HumanBodyActionCounter())
let cameraFrames = readCamera(configuration: cameraConfig)
for await count in liveActionCounter.applied(to: cameraFrames) {
updateCountLabel(count)
}
// 增量训练声音分类器
let featureExtractor = AudioFeaturePrint()
let classifier = LogisticRegressionClassifier()
let soundClassifier = featureExtractor.appending(classifier)
// 预处理:只对数据做一次特征提取
let features = try await featureExtractor.preprocessed(data)
// 后续训练只使用缓存的特征
let model = try await classifier.fitted(to: features)最佳实践
- 视频分析管线中先用 Sliding Window 分组再处理,平衡精度和实时性
- 摄像头场景调小 stride 值以获得更快的响应,但不要太小导致计算开销过大
- 增量训练时务必缓存预处理后的特征,避免重复计算
- 动作计数器的输出是浮点数,包含部分动作的计数——需要根据业务需求决定是否取整
- 测试时使用不同光照和角度条件验证模型的鲁棒性
还有什么值得关注
- “Get to know Create ML Components” 是前置必看内容
- “What’s new in Create ML” 介绍了 Create ML App 的新功能
- Vision 框架的 Human Body Pose 是底层依赖
- Create ML Components 是开源的,可以在 GitHub 上查看实现
WWDC 2022